Code review is the single biggest bottleneck in most engineering teams — and the quality of reviews degrades the more you need them.
Every engineering team has the same problem. Pull requests pile up. Senior developers spend 4-6 hours a day reviewing code instead of building features. Junior developers wait hours — sometimes days — for feedback. And when that feedback finally arrives, it's inconsistent: one reviewer cares about error handling, another focuses on naming conventions, and nobody catches the SQL injection vulnerability hiding on line 47.
The math doesn't work. A 2024 study by LinearB found that the average PR waits 24 hours for the first review, and teams with review bottlenecks ship 40% slower than those without. Static analysis tools help with syntax and linting, but they can't reason about business logic, catch architectural anti-patterns, or explain why something is a problem.
In this two-part series, I'll walk through building an AI-powered code review assistant that uses specialized agents for different review concerns — security analysis, performance review, bug detection, and style consistency — orchestrated through a unified pipeline using Azure OpenAI, Python (LangGraph), and C# (Semantic Kernel).
What You'll Learn
- How to parse and structure git diffs for LLM consumption
- Multi-agent architecture for specialized review concerns
- Orchestrating parallel review agents with LangGraph and Semantic Kernel
- Aggregating and deduplicating findings across agents
- Severity classification and actionable feedback generation
- ROI framework for AI-assisted code review
Reading time: 13 minutes | Implementation time: 2-3 days
The Current State of Code Review
Most teams rely on a combination of manual peer review and static analysis. The typical workflow looks like this: a developer opens a pull request, a linter runs in CI to catch formatting issues, and one or two human reviewers are assigned.
This approach has worked for decades, but it breaks down at scale:
- Reviewer fatigue. After reviewing 200-400 lines of code, defect detection rates drop by 70% (Cisco Systems study). Most production PRs exceed this threshold.
- Inconsistent coverage. Human reviewers have blind spots. A backend developer reviewing frontend code will miss React anti-patterns. A junior reviewer won't catch subtle race conditions.
- Context switching cost. Every review interruption costs a developer 15-25 minutes of context-switching overhead (University of California, Irvine). With 3-5 reviews per day, that's 1-2 hours lost.
- Static analysis limitations. Tools like ESLint, SonarQube, and Pylint catch syntax-level issues but can't reason about business logic, architectural patterns, or semantic vulnerabilities.
The gap between "what a linter catches" and "what a senior reviewer catches" is exactly where AI can help. Not as a replacement for human review — you still need humans for architectural decisions, business logic validation, and mentoring — but as a first pass that catches the 60-70% of issues that are mechanical.
The Goal: First-Pass Review
The AI review assistant isn't replacing human reviewers. It's doing the tedious first pass — catching null pointer risks, SQL injection patterns, missing error handling, and style violations — so human reviewers can focus on architecture, business logic, and mentoring.
The Multi-Agent Review Approach
Instead of sending the entire diff to one LLM with a massive prompt ("review this code for everything"), I split the review into specialized agents, each focused on one concern. This is the same principle behind good software architecture: single responsibility.
Four specialized agents handle distinct review categories:
- Security Agent — Scans for OWASP Top 10 vulnerabilities, injection patterns, authentication flaws, and secrets exposure
- Performance Agent — Identifies N+1 queries, unnecessary allocations, missing caching opportunities, and algorithmic complexity issues
- Bug Detection Agent — Catches null reference risks, off-by-one errors, race conditions, unhandled edge cases, and logic errors
- Style Agent — Enforces naming conventions, code organization, documentation standards, and team-specific patterns
Why not one big prompt? Three reasons:
- Focused prompts produce better results. An LLM with a narrow task ("find security vulnerabilities") outperforms one with a broad task ("review everything") because the prompt can include domain-specific context, examples, and heuristics.
- Parallel execution. Four agents running simultaneously complete faster than one sequential mega-review.
- Independent tuning. You can adjust the security agent's sensitivity without affecting style checks. You can swap out the performance agent's model without touching bug detection.
The tech stack:
| Component | Python | C# |
|---|---|---|
| Orchestration | LangGraph | Semantic Kernel |
| LLM | Azure OpenAI (GPT-4o) | Azure OpenAI (GPT-4o) |
| Diff Parsing | unidiff / custom parser | DiffPlex / custom parser |
| Finding Storage | Pydantic models | Record types |
Architecture Overview
The system takes a git diff as input and produces a structured review with categorized findings, severity levels, and actionable suggestions. Here's how the components fit together:
- Diff Parser — Converts raw git diff into structured file-level changes with context
- Review Orchestrator — Manages the review pipeline, dispatches to agents, collects results
- Security Agent — OWASP-focused vulnerability scanning
- Performance Agent — Complexity and efficiency analysis
- Bug Detection Agent — Logic and correctness review
- Style Agent — Convention and readability enforcement
- Finding Aggregator — Deduplicates, prioritizes, and formats the final review
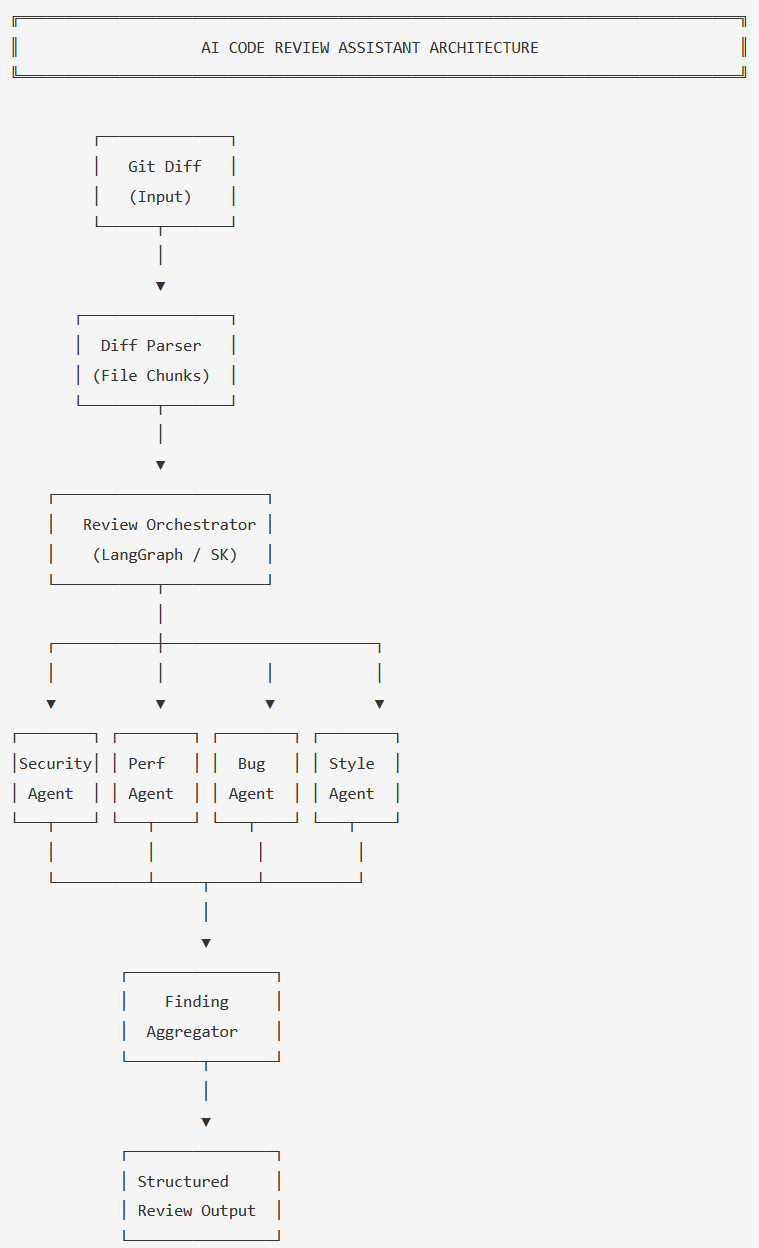
The orchestrator dispatches file chunks to four parallel agents, then aggregates findings into a unified review
The key design decision is running agents in parallel rather than sequentially. Each agent receives the same diff chunks but reviews from a different perspective. The Finding Aggregator then deduplicates overlapping findings — if both the Security Agent and the Bug Detection Agent flag the same unvalidated input, the aggregator merges them into a single finding with the higher severity.
Core Implementation
Data Models
First, we need to define the structures that flow through the system. Every review finding has a severity, a category, a file location, and a suggestion.
from enum import Enum
from pydantic import BaseModel
from typing import List, Optional
class Severity(str, Enum):
CRITICAL = "critical"
HIGH = "high"
MEDIUM = "medium"
LOW = "low"
INFO = "info"
class ReviewCategory(str, Enum):
SECURITY = "security"
PERFORMANCE = "performance"
BUG = "bug"
STYLE = "style"
class Finding(BaseModel):
category: ReviewCategory
severity: Severity
file_path: str
line_start: int
line_end: Optional[int] = None
title: str
description: str
suggestion: str
confidence: float # 0.0 - 1.0
class ReviewResult(BaseModel):
findings: List[Finding]
files_reviewed: int
summary: str
class DiffChunk(BaseModel):
file_path: str
language: str
added_lines: List[dict] # {line_num, content}
removed_lines: List[dict]
context_before: str
context_after: strpublic enum Severity
{
Critical, High, Medium, Low, Info
}
public enum ReviewCategory
{
Security, Performance, Bug, Style
}
public record Finding(
ReviewCategory Category,
Severity Severity,
string FilePath,
int LineStart,
int? LineEnd,
string Title,
string Description,
string Suggestion,
double Confidence // 0.0 - 1.0
);
public record ReviewResult(
List<Finding> Findings,
int FilesReviewed,
string Summary
);
public record DiffChunk(
string FilePath,
string Language,
List<DiffLine> AddedLines,
List<DiffLine> RemovedLines,
string ContextBefore,
string ContextAfter
);
public record DiffLine(int LineNum, string Content);Review Orchestrator
The orchestrator is the heart of the system. It takes parsed diff chunks, dispatches them to all four agents in parallel, and collects the results.
from langgraph.graph import StateGraph, END
from typing import TypedDict, List
import asyncio
class ReviewState(TypedDict):
diff_chunks: List[dict]
security_findings: List[dict]
performance_findings: List[dict]
bug_findings: List[dict]
style_findings: List[dict]
aggregated_findings: List[dict]
summary: str
def build_review_graph() -> StateGraph:
workflow = StateGraph(ReviewState)
# Add review agent nodes
workflow.add_node("security_review", security_agent)
workflow.add_node("performance_review", performance_agent)
workflow.add_node("bug_review", bug_detection_agent)
workflow.add_node("style_review", style_agent)
workflow.add_node("aggregate", aggregate_findings)
# Fan-out: all agents run in parallel
workflow.set_entry_point("security_review")
workflow.add_edge("security_review", "performance_review")
workflow.add_edge("performance_review", "bug_review")
workflow.add_edge("bug_review", "style_review")
# Fan-in: aggregate after all agents complete
workflow.add_edge("style_review", "aggregate")
workflow.add_edge("aggregate", END)
return workflow.compile()
async def run_review(diff_chunks: List[DiffChunk]) -> ReviewResult:
graph = build_review_graph()
initial_state = {
"diff_chunks": [c.model_dump() for c in diff_chunks],
"security_findings": [],
"performance_findings": [],
"bug_findings": [],
"style_findings": [],
"aggregated_findings": [],
"summary": "",
}
result = await graph.ainvoke(initial_state)
return ReviewResult(
findings=[Finding(**f) for f in result["aggregated_findings"]],
files_reviewed=len(diff_chunks),
summary=result["summary"],
)using Microsoft.SemanticKernel;
public class ReviewOrchestrator
{
private readonly SecurityAgent _security;
private readonly PerformanceAgent _performance;
private readonly BugDetectionAgent _bugDetection;
private readonly StyleAgent _style;
private readonly FindingAggregator _aggregator;
public ReviewOrchestrator(Kernel kernel)
{
_security = new SecurityAgent(kernel);
_performance = new PerformanceAgent(kernel);
_bugDetection = new BugDetectionAgent(kernel);
_style = new StyleAgent(kernel);
_aggregator = new FindingAggregator();
}
public async Task<ReviewResult> RunReviewAsync(
List<DiffChunk> chunks)
{
// Run all agents in parallel
var tasks = new[]
{
_security.ReviewAsync(chunks),
_performance.ReviewAsync(chunks),
_bugDetection.ReviewAsync(chunks),
_style.ReviewAsync(chunks),
};
var results = await Task.WhenAll(tasks);
// Aggregate findings from all agents
var allFindings = results
.SelectMany(r => r)
.ToList();
var aggregated = _aggregator
.Aggregate(allFindings);
return new ReviewResult(
aggregated,
chunks.Count,
GenerateSummary(aggregated)
);
}
private string GenerateSummary(
List<Finding> findings)
{
var critical = findings
.Count(f => f.Severity == Severity.Critical);
var high = findings
.Count(f => f.Severity == Severity.High);
return $"Found {findings.Count} issues: " +
$"{critical} critical, {high} high priority";
}
}Why LangGraph for Python?
LangGraph gives us a state machine with explicit edges between nodes. This matters for code review because we want deterministic flow control — every diff always goes through all four agents, and the aggregation step always runs last. LangGraph's state graph makes this explicit and debuggable, unlike ad-hoc async chains.
Challenge #1: Parsing Diffs for LLM Consumption
Raw git diffs are designed for humans and tools like patch — not for
LLMs. A naive approach of sending the raw diff as a string works for small changes, but
breaks down quickly. LLMs need structured context: which file was changed, what was
added vs. removed, and enough surrounding code to understand the change.
The diff parser converts raw unified diff format into structured chunks that each agent can reason about:
from unidiff import PatchSet
from typing import List
LANGUAGE_MAP = {
".py": "python", ".cs": "csharp",
".js": "javascript", ".ts": "typescript",
".java": "java", ".go": "go",
}
def parse_diff(raw_diff: str) -> List[DiffChunk]:
"""Parse unified diff into structured chunks."""
patch = PatchSet(raw_diff)
chunks = []
for patched_file in patch:
ext = patched_file.path.rsplit(".", 1)[-1]
language = LANGUAGE_MAP.get(f".{ext}", "unknown")
added, removed = [], []
for hunk in patched_file:
for line in hunk:
if line.is_added:
added.append({
"line_num": line.target_line_no,
"content": line.value.rstrip(),
})
elif line.is_removed:
removed.append({
"line_num": line.source_line_no,
"content": line.value.rstrip(),
})
# Extract context (3 lines before/after each hunk)
context_before = _extract_context(
patched_file, position="before", lines=3
)
context_after = _extract_context(
patched_file, position="after", lines=3
)
chunks.append(DiffChunk(
file_path=patched_file.path,
language=language,
added_lines=added,
removed_lines=removed,
context_before=context_before,
context_after=context_after,
))
return chunksusing DiffPlex;
using DiffPlex.DiffBuilder;
using DiffPlex.DiffBuilder.Model;
public class DiffParser
{
private static readonly Dictionary<string, string>
LanguageMap = new()
{
[".py"] = "python", [".cs"] = "csharp",
[".js"] = "javascript", [".ts"] = "typescript",
[".java"] = "java", [".go"] = "go",
};
public List<DiffChunk> Parse(string rawDiff)
{
var chunks = new List<DiffChunk>();
var files = SplitByFile(rawDiff);
foreach (var file in files)
{
var ext = Path.GetExtension(file.Path);
var language = LanguageMap
.GetValueOrDefault(ext, "unknown");
var added = new List<DiffLine>();
var removed = new List<DiffLine>();
foreach (var hunk in file.Hunks)
{
foreach (var line in hunk.Lines)
{
if (line.Type == ChangeType.Inserted)
added.Add(new DiffLine(
line.Position, line.Text));
else if (line.Type == ChangeType.Deleted)
removed.Add(new DiffLine(
line.Position, line.Text));
}
}
chunks.Add(new DiffChunk(
file.Path,
language,
added,
removed,
ExtractContext(file, "before", 3),
ExtractContext(file, "after", 3)
));
}
return chunks;
}
}The critical detail is the context window. Each chunk includes 3 lines
before and after the change so agents can understand the surrounding code. Without this,
an agent might flag user_input as unsanitized when the sanitization happens
on the line above the diff boundary.
Token Budget Warning
Large PRs with 50+ files can blow past token limits. In practice, I chunk files individually and cap each agent call at ~4,000 tokens of diff content. If a single file exceeds this, I split by hunk boundaries. More on token cost management in Part 2.
Challenge #2: Building the Security Review Agent
The security agent is the most nuanced of the four because false positives erode developer trust faster than any other category. If the agent flags a parameterized query as "SQL injection risk," developers will start ignoring all security findings. The prompt needs to be precise about what constitutes a real vulnerability vs. a safe pattern.
SECURITY_PROMPT = """You are a security-focused code reviewer.
Analyze the following code diff for security vulnerabilities.
FOCUS ON:
- SQL injection (string concatenation in queries)
- XSS (unescaped user input in HTML output)
- Command injection (user input in shell commands)
- Path traversal (user input in file paths)
- Hardcoded secrets (API keys, passwords, tokens)
- Authentication/authorization bypasses
- Insecure deserialization
DO NOT FLAG:
- Parameterized queries (these are SAFE)
- Framework-provided CSRF protection
- Input already sanitized by middleware
- Test files with mock credentials
For each finding, provide:
- severity: critical/high/medium/low
- line_start: the line number
- title: one-line summary
- description: what the vulnerability is
- suggestion: how to fix it
- confidence: 0.0-1.0
Respond as JSON array of findings. If no issues, return [].
"""
async def security_agent(state: ReviewState) -> ReviewState:
findings = []
for chunk in state["diff_chunks"]:
prompt = f"""{SECURITY_PROMPT}
File: {chunk['file_path']} ({chunk['language']})
Context before change:
{chunk['context_before']}
Added lines:
{_format_lines(chunk['added_lines'])}
Removed lines:
{_format_lines(chunk['removed_lines'])}
Context after change:
{chunk['context_after']}
"""
response = await llm.chat(
[{"role": "user", "content": prompt}],
temperature=0,
response_format={"type": "json_object"},
)
chunk_findings = parse_findings(
response, ReviewCategory.SECURITY
)
findings.extend(chunk_findings)
state["security_findings"] = [
f.model_dump() for f in findings
]
return statepublic class SecurityAgent
{
private readonly Kernel _kernel;
private const string SecurityPrompt = @"
You are a security-focused code reviewer.
Analyze the following code diff for vulnerabilities.
FOCUS ON:
- SQL injection (string concatenation in queries)
- XSS (unescaped user input in HTML output)
- Command injection (user input in shell commands)
- Path traversal (user input in file paths)
- Hardcoded secrets (API keys, passwords, tokens)
- Authentication/authorization bypasses
DO NOT FLAG:
- Parameterized queries (these are SAFE)
- Framework-provided CSRF protection
- Input already sanitized by middleware
- Test files with mock credentials
Return JSON array of findings with: severity,
line_start, title, description, suggestion,
confidence. Return [] if no issues.";
public SecurityAgent(Kernel kernel)
=> _kernel = kernel;
public async Task<List<Finding>> ReviewAsync(
List<DiffChunk> chunks)
{
var findings = new List<Finding>();
foreach (var chunk in chunks)
{
var prompt = $@"{SecurityPrompt}
File: {chunk.FilePath} ({chunk.Language})
Context before: {chunk.ContextBefore}
Added lines:
{FormatLines(chunk.AddedLines)}
Removed lines:
{FormatLines(chunk.RemovedLines)}
Context after: {chunk.ContextAfter}";
var fn = _kernel
.CreateFunctionFromPrompt(prompt);
var result = await _kernel
.InvokeAsync(fn);
var parsed = JsonSerializer
.Deserialize<List<FindingDto>>(
result.ToString());
findings.AddRange(parsed.Select(
f => f.ToFinding(
ReviewCategory.Security,
chunk.FilePath)));
}
return findings;
}
}The "DO NOT FLAG" section is critical. Without explicit exclusions, the LLM will flag every database query as a potential injection risk regardless of whether it uses parameterized queries. This is the difference between a useful tool and a noise generator.
I also set temperature=0 for all review agents. Security analysis needs to
be deterministic — the same code should produce the same findings every time.
Creative writing has no place in vulnerability detection.
The confidence score is the secret weapon. Findings below 0.6 confidence get flagged as "suggestions" rather than "issues" in the final output. This reduces false-positive fatigue without hiding potentially real problems.
ROI: When AI Code Review Pays Off
The business case for AI-assisted code review comes down to three numbers: time saved per review, defects caught earlier, and developer satisfaction.
| Metric | Before (Manual Only) | After (AI + Manual) |
|---|---|---|
| Avg. time to first review feedback | 24 hours | 5 minutes (AI) + 4 hours (human) |
| Mechanical issues caught per PR | 3-5 (inconsistent) | 8-12 (consistent) |
| Senior dev time on reviews/day | 4-6 hours | 2-3 hours |
| Security issues reaching production | ~2/quarter | ~0.5/quarter |
| Review cost per PR (AI tokens) | $0 | $0.08-$0.25 |
ROI Framework
For a team of 10 developers doing 15 PRs/day:
- Time saved: 2 hours/day × 5 senior devs = 10 hours/day = ~$1,500/day at $150/hr loaded cost
- AI cost: 15 PRs × $0.15 avg = $2.25/day
- Net savings: ~$1,497/day or ~$32,000/month
- Security value: Preventing 1 production vulnerability saves $50K-$500K in incident response
Break-even happens on day one. The token costs are negligible compared to developer time.
The less quantifiable benefit is developer experience. Junior developers get immediate feedback on every PR instead of waiting overnight. The feedback is consistent — the same patterns get flagged the same way every time. And senior developers spend their review time on architecture and mentoring instead of pointing out missing null checks.
When This Doesn't Pay Off
- Solo developer. If you're the only reviewer and you trust your own code, the overhead of maintaining the system isn't worth it.
- Very small teams (<3 devs). Review bottlenecks don't exist when everyone can review within an hour.
- Highly regulated industries. If you need a human to legally sign off on every change anyway, AI review adds cost without reducing compliance burden.
What's Next
In Part 1, we covered the architecture and core implementation of an AI code review assistant: diff parsing, parallel multi-agent review, the security agent's prompt engineering, and the business case.
But shipping this to production raises real questions. How much does it actually cost per PR when you account for large diffs and retries? How do you trace why an agent flagged (or missed) a finding? When should you choose LangGraph vs. Semantic Kernel? And when is this whole approach overkill?
Part 2 covers all of that: cost analysis with real token numbers, observability and debugging patterns, Python vs. C# decision framework, Azure infrastructure, and an honest look at when you should skip AI review entirely.
Part 2: Production Considerations
Part 2 covers cost analysis per review, observability patterns for tracing agent decisions, Python vs C# trade-offs, Azure infrastructure, and when NOT to use AI code review. Subscribe below to get notified when it's published.
Read Part 2 →This article demonstrates AI-assisted code review concepts. Production code would need error handling, rate limiting, token budget management, and proper state persistence.
Want More Practical AI Tutorials?
I write about building production AI systems with Azure, Python, and C#. Subscribe for practical tutorials delivered twice a month.
Subscribe to Newsletter →