Most e-commerce "personalization" is just purchase history recycling. The hard problem isn't showing customers what they already bought — it's knowing where they are in their decision journey right now, and orchestrating every experiment and content decision around that.
Here's what I see in most mid-size e-commerce teams: three separate squads running A/B tests simultaneously. The growth team is testing a free-shipping banner. The checkout team is testing a new payment flow. The merchandising team is testing product placement. No one is checking whether the same customer is enrolled in all three. No one knows if the free-shipping experiment is actually cannibalizing the checkout flow test's results. And nobody has connected these experiments to any model of where each customer is in their buying journey.
Traditional A/B testing tools — Optimizely, VWO, LaunchDarkly — operate at the presentation layer. They're excellent at splitting traffic and measuring click-through rates. But they're blind to journey state: whether this particular customer viewed the same product twice last week, added it to their wishlist, and is now on their third session specifically searching for a discount. A customer at that point of intent needs a completely different experience than someone browsing casually for the first time.
I built a four-agent orchestration system that solves this: a Journey Tracker that maintains real-time customer journey state, an Experiment Agent that prevents conflicting assignments using semantic conflict detection, a Personalization Agent that generates contextual content calibrated to journey stage, and an Analytics Agent that monitors experiment significance and flags auto-promotion candidates. In this article, I'll walk through the architecture, the core implementation in both Python (LangGraph) and C# (Semantic Kernel), and the two technical challenges that made this interesting to build.
What You'll Learn
- How to model real-time customer journey state as a LangGraph
TypedDictand Semantic Kernel data class - Event-driven orchestration: routing behavioral signals to specialized agents via Azure Event Hubs
- Semantic conflict detection: using an LLM to prevent customers from being enrolled in contradictory experiments
- Journey-aware personalization: classifying customers into discovery, consideration, intent, and retention stages
- The ROI framework for when this approach pays off vs. when a rule engine is enough
Current Approach & Limitations
The typical e-commerce stack for personalization and experimentation looks like this: a feature flagging tool for A/B tests, a recommendation engine (often a vendor-provided black box), static customer segments like "returning buyer" or "cart abandoner," and rule-based promotion logic. It's assembled piecemeal over years, each tool solving a narrow problem.
The limitations become obvious at scale:
Experiment conflicts. When multiple teams run concurrent A/B tests, they frequently overlap on the same customers. A customer enrolled in a checkout UX experiment, a discount banner test, and a product recommendation test simultaneously is receiving three simultaneous changes to their experience. Any statistical lift (or drag) you observe is confounded noise — you can't attribute it to any single experiment. In my experience, teams running more than five concurrent tests typically have a conflict rate exceeding 30% without realizing it.
No journey awareness. Static segments don't capture intent. "Returning visitor" tells you someone has been to your site before. It tells you nothing about whether they've viewed the same product four times, added it to their cart, and are now hunting for a coupon code. That distinction matters enormously for what content to show them. A "15% off" banner shown to someone in active consideration mode converts at 3-4x the rate of the same banner shown to someone casually browsing.
Slow iteration cycles. Traditional A/B tests often need two to four weeks to reach statistical significance at 95% confidence, particularly for lower-traffic pages. Teams compensate by running fewer, bigger bets — which means less learning overall. An agent that monitors significance continuously and flags winners early compresses the iteration cycle.
Siloed behavioral signals. Search queries, product views, cart events, wishlist additions — these signals live in separate systems. Connecting them into a coherent customer journey model requires data engineering effort that most teams defer indefinitely.
The Solution Approach
The core insight is that customer journey orchestration is an event-driven problem, not a batch analytics problem. Every customer action — a page view, a search query, an add-to-cart — is a signal that should update journey state and potentially trigger an experiment assignment or personalization decision in near-real-time. Polling a data warehouse at midnight doesn't give you that.
I structured this as four specialized agents, each with a single responsibility:
- Journey Tracker Agent — Consumes events from Azure Event Hubs, updates a persistent journey model in Cosmos DB, and classifies the customer's current journey stage using a constrained LLM call.
- Experiment Agent — Given a customer's current journey state and the full list of active experiments, assigns the customer to eligible experiments while detecting and preventing semantic conflicts using GPT-4o.
- Personalization Agent — Queries Azure AI Search for relevant products and content, then generates a personalization recommendation calibrated to the customer's journey stage and active experiment variants.
- Analytics Agent — Records experiment exposure and conversion events, runs rolling statistical significance calculations, and surfaces auto-promotion candidates when a variant achieves significance.
The orchestrator routes incoming events to the appropriate agents using LangGraph's conditional edge system (Python) or Semantic Kernel's process framework (C#). Not every event triggers all four agents — a page view updates journey state but doesn't necessarily trigger experiment re-assignment if the customer already has active allocations.
Tech stack:
| Layer | Technology | Role |
|---|---|---|
| Event ingestion | Azure Event Hubs | Real-time customer event stream |
| Orchestration (Python) | LangGraph | Agent graph with conditional routing |
| Orchestration (C#) | Semantic Kernel | Process framework with plugin agents |
| AI reasoning | Azure OpenAI (GPT-4o) | Journey classification, conflict detection |
| Journey store | Azure Cosmos DB | Persistent event log per customer |
| Session state | Azure Cache for Redis | Hot journey state for low-latency reads |
| Product catalog | Azure AI Search | Hybrid retrieval for personalization |
Architecture Overview
The system is event-driven end-to-end. Customer actions on the storefront publish events to Azure Event Hubs. The orchestrator consumes these events, classifies them, and routes to the relevant agents. All persistent state flows through Cosmos DB; hot session state is cached in Redis for sub-10ms reads during the personalization path.
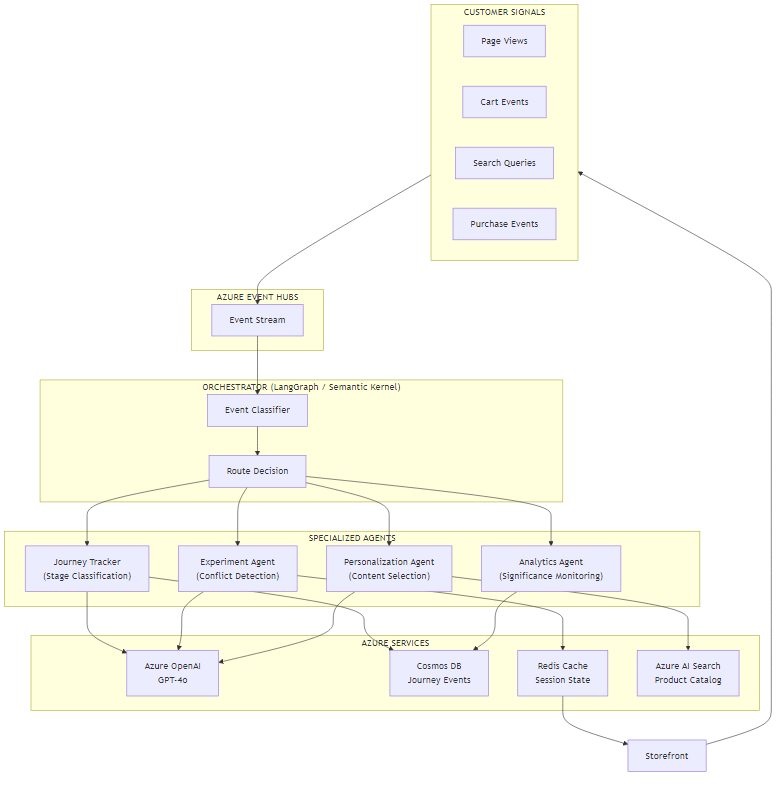
The key architectural decision was making journey state the central source of truth, not the experiment assignment. Experiments are derived from journey state, not the reverse. This means when journey stage changes — say, a customer moves from "consideration" to "intent" — the Experiment Agent can re-evaluate assignments without needing a full re-enrolment mechanism.
Data flow for a typical cart add event:
- Storefront publishes
cart.item_addedevent to Event Hubs withcustomer_id,product_id, and session context - Orchestrator receives the event and routes to Journey Tracker first
- Journey Tracker updates the customer's event log in Cosmos DB and reclassifies journey stage (typically moves from "consideration" to "intent" on first cart add)
- Orchestrator then routes to Experiment Agent, which checks whether the stage change requires experiment re-evaluation
- Experiment Agent runs conflict detection and returns a final cohort assignment
- Personalization Agent queries AI Search for complementary products matching the cart item, generates a contextual recommendation
- Analytics Agent records the exposure event for active experiments
- Final response is written to Redis; the storefront reads from Redis on next page render
Why Event Hubs Instead of Direct API Calls?
During peak traffic (Black Friday, flash sales), a direct synchronous API would create back-pressure on the storefront. Event Hubs decouples event production from processing, absorbs traffic spikes, and guarantees at-least-once delivery. The orchestrator processes events asynchronously — the storefront doesn't wait for a response to render the page, it reads from Redis on the next request cycle.
Core Implementation
State Model
The journey state carries everything the agents need: the customer's event history, their
current journey stage, their active experiment assignments, and the most recent
personalization context. I keep the full event list in state for the LangGraph version
because the Journey Tracker needs it for stage classification — but I use
operator.add to append rather than replace, so events accumulate across
graph invocations.
from typing import TypedDict, List, Dict, Annotated, Optional
import operator
class CustomerJourneyState(TypedDict):
"""Central state object passed through the agent graph."""
customer_id: str
session_id: str
# operator.add appends events across graph invocations
events: Annotated[List[dict], operator.add]
journey_stage: str # discovery | consideration | intent | purchase | retention
active_experiments: Dict[str, str] # experiment_id -> variant_id
personalization_context: Optional[dict]
last_event_type: str
response: Optional[dict]public enum JourneyStage
{
Discovery, Consideration, Intent, Purchase, Retention
}
public class CustomerJourneyState
{
public string CustomerId { get; set; }
public string SessionId { get; set; }
public List<CustomerEvent> Events { get; set; } = new();
public JourneyStage Stage { get; set; } = JourneyStage.Discovery;
// Maps experimentId -> variantId
public Dictionary<string, string> ActiveExperiments { get; set; } = new();
public PersonalizationContext? PersonalizationContext { get; set; }
public string LastEventType { get; set; }
public OrchestrationResult? Response { get; set; }
}Orchestrator Graph
The orchestrator uses conditional edges to route events to agents based on event type. Not every event needs all agents. A purchase event skips the Personalization Agent (the journey is done) and goes straight to Analytics. A search query updates journey state and triggers personalization but skips experiment re-assignment if the customer already has active allocations.
from langgraph.graph import StateGraph, END
from agents import journey_tracker, experiment_agent, personalization_agent, analytics_agent
def route_event(state: CustomerJourneyState) -> str:
event_type = state["last_event_type"]
if event_type in ("purchase", "order_complete"):
return "analytics"
if event_type in ("page_view", "search"):
return "journey_tracker"
if event_type in ("cart_add", "cart_remove", "wishlist_add"):
return "journey_tracker"
return "journey_tracker"
def needs_experiment_assignment(state: CustomerJourneyState) -> str:
# Re-assign if no active experiments OR stage just changed
if not state["active_experiments"]:
return "experiment_agent"
return "personalization_agent"
def build_journey_graph() -> StateGraph:
workflow = StateGraph(CustomerJourneyState)
workflow.add_node("journey_tracker", journey_tracker.process)
workflow.add_node("experiment_agent", experiment_agent.process)
workflow.add_node("personalization_agent", personalization_agent.process)
workflow.add_node("analytics_agent", analytics_agent.process)
workflow.set_entry_point("journey_tracker")
workflow.add_conditional_edges(
"journey_tracker",
needs_experiment_assignment,
{
"experiment_agent": "experiment_agent",
"personalization_agent": "personalization_agent",
}
)
workflow.add_edge("experiment_agent", "personalization_agent")
workflow.add_edge("personalization_agent", "analytics_agent")
workflow.add_edge("analytics_agent", END)
return workflow.compile()using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Process;
public class JourneyOrchestrator
{
private readonly Kernel _kernel;
public JourneyOrchestrator(Kernel kernel)
{
_kernel = kernel;
}
public KernelProcess BuildProcess()
{
var builder = new ProcessBuilder("CustomerJourneyProcess");
var trackerStep = builder.AddStepFromType<JourneyTrackerStep>();
var experimentStep = builder.AddStepFromType<ExperimentAgentStep>();
var personalizeStep = builder.AddStepFromType<PersonalizationStep>();
var analyticsStep = builder.AddStepFromType<AnalyticsStep>();
builder.OnInputEvent(JourneyEvents.CustomerEvent)
.SendEventTo(trackerStep.WhereInputEventIs(JourneyEvents.TrackEvent));
trackerStep.OnEvent(JourneyEvents.TrackComplete)
.SendEventTo(experimentStep.WhereInputEventIs(JourneyEvents.EvaluateExperiments));
experimentStep.OnEvent(JourneyEvents.ExperimentsAssigned)
.SendEventTo(personalizeStep.WhereInputEventIs(JourneyEvents.Personalize));
personalizeStep.OnEvent(JourneyEvents.PersonalizationReady)
.SendEventTo(analyticsStep.WhereInputEventIs(JourneyEvents.RecordExposure));
return builder.Build();
}
}Challenge 1: Semantic Experiment Conflict Detection
This is the part I found most interesting to build. The naive approach to conflict detection is a mutex: define which experiments are mutually exclusive at configuration time, then check a lookup table during assignment. That works if someone remembers to update the lookup table every time a new experiment launches. In practice, teams forget.
The problem with rule-based conflict detection is semantic: two experiments can conflict even when they don't share an obvious mutex. Consider a free-shipping threshold experiment ("free shipping over $75") running concurrently with a cart-value discount experiment ("10% off orders over $100"). These operate on different UI components. A rule-based system would allow them to co-enroll the same customer. But they're testing contradictory economic incentives — you can't cleanly attribute conversion lift to either one.
I used GPT-4o to detect semantic conflicts at assignment time. The prompt is constrained:
it only needs to return a boolean plus a reason string. I use temperature=0
and response_format: json_object to make the output deterministic.
import json
from openai import AsyncAzureOpenAI
CONFLICT_PROMPT = """
You detect whether two A/B experiments conflict.
Conflicts occur when experiments:
1. Modify the same UI element or page region
2. Test contradictory economic incentives (e.g., discount vs. price anchor)
3. Would produce unreliable combined results due to interaction effects
Experiment A: {exp_a}
Experiment B: {exp_b}
Respond ONLY with valid JSON: {{"conflicts": true/false, "reason": "brief explanation"}}
"""
async def check_conflict(
exp_a: dict,
exp_b: dict,
client: AsyncAzureOpenAI
) -> dict:
response = await client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are an experiment conflict detector. Return only JSON."},
{"role": "user", "content": CONFLICT_PROMPT.format(
exp_a=json.dumps(exp_a, indent=2),
exp_b=json.dumps(exp_b, indent=2)
)}
],
temperature=0,
response_format={"type": "json_object"},
max_tokens=100
)
return json.loads(response.choices[0].message.content)
async def assign_experiments(
state: CustomerJourneyState,
available_experiments: list[dict],
client: AsyncAzureOpenAI
) -> dict[str, str]:
"""Assign non-conflicting experiments to a customer."""
assigned = {}
already_assigned = list(available_experiments)
for experiment in available_experiments:
# Check against all already-assigned experiments
is_clear = True
for assigned_exp in list(assigned.values()):
result = await check_conflict(experiment, assigned_exp, client)
if result["conflicts"]:
is_clear = False
break
if is_clear:
# Deterministic variant assignment using customer_id hash
import hashlib
hash_val = int(hashlib.md5(
f"{state['customer_id']}-{experiment['id']}".encode()
).hexdigest(), 16)
variant = experiment["variants"][hash_val % len(experiment["variants"])]
assigned[experiment["id"]] = variant["id"]
return assignedusing Microsoft.SemanticKernel;
using System.Text.Json;
public class ExperimentAgentStep : KernelProcessStep
{
private const string ConflictPrompt = """
You detect whether two A/B experiments conflict.
Conflicts occur when experiments:
1. Modify the same UI element or page region
2. Test contradictory economic incentives (e.g., discount vs. price anchor)
3. Would produce unreliable combined results due to interaction effects
Experiment A: {exp_a}
Experiment B: {exp_b}
Respond ONLY with valid JSON: {"conflicts": true/false, "reason": "brief explanation"}
""";
[KernelFunction]
public async Task<ExperimentResult> EvaluateExperimentsAsync(
KernelProcessStepContext context,
CustomerJourneyState state,
List<Experiment> availableExperiments,
Kernel kernel)
{
var assigned = new Dictionary<string, string>();
foreach (var experiment in availableExperiments)
{
bool isConflict = false;
foreach (var (expId, _) in assigned)
{
var alreadyAssigned = availableExperiments.First(e => e.Id == expId);
var prompt = ConflictPrompt
.Replace("{exp_a}", JsonSerializer.Serialize(experiment))
.Replace("{exp_b}", JsonSerializer.Serialize(alreadyAssigned));
var result = await kernel.InvokePromptAsync<ConflictResult>(prompt);
if (result.Conflicts)
{
isConflict = true;
break;
}
}
if (!isConflict)
{
// Deterministic hash-based variant assignment
var hashBytes = System.Security.Cryptography.MD5.HashData(
System.Text.Encoding.UTF8.GetBytes($"{state.CustomerId}-{experiment.Id}"));
var hashVal = BitConverter.ToInt32(hashBytes, 0);
var variant = experiment.Variants[Math.Abs(hashVal) % experiment.Variants.Count];
assigned[experiment.Id] = variant.Id;
}
}
await context.EmitEventAsync(JourneyEvents.ExperimentsAssigned,
new ExperimentResult { Assignments = assigned });
return new ExperimentResult { Assignments = assigned };
}
}Cost Consideration: LLM Conflict Detection
Checking N experiments against each other is O(N²) in LLM calls. For a catalogue of 20 active experiments, that's up to 190 calls per customer event if you're naive about it. In practice, you cache conflict results (experiment pair A + experiment pair B always produces the same result), which reduces this to O(N²) unique pairs — computed once and stored. With 20 experiments, that's 190 cached conflict decisions, not 190 calls per event.
Challenge 2: Journey-Aware Personalization
Showing the right content at the right journey stage is more nuanced than it sounds. "Free shipping on orders over $75" is a high-converting banner for a customer with an $80 cart who's wavering. The same banner shown to a customer who just landed on the homepage for the first time interrupts their discovery flow and can actually reduce engagement — they haven't decided what they want yet, and a threshold-based incentive feels premature.
The Personalization Agent first classifies the customer's current journey stage using a constrained LLM call over their recent event history, then selects content from a predefined pool calibrated for each stage.
from openai import AsyncAzureOpenAI
STAGE_PROMPT = """
Classify this customer's current journey stage from their recent behavioral events.
Stages:
- discovery: browsing broadly, no repeated product views, no cart activity
- consideration: viewed same product 2+ times OR added to wishlist
- intent: has items in cart, started checkout flow, or searched for discount codes
- purchase: completed a purchase in the last 30 days
- retention: returning after purchase, browsing accessories or replenishment items
Recent events (newest first, last 10):
{events}
Return ONLY the stage name (one of: discovery, consideration, intent, purchase, retention).
"""
async def classify_stage(
events: list[dict],
client: AsyncAzureOpenAI
) -> str:
recent = events[-10:] if len(events) > 10 else events
events_text = "\n".join([
f"- {e['type']}: product={e.get('product_id', 'n/a')} at {e['timestamp']}"
for e in reversed(recent)
])
response = await client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": STAGE_PROMPT.format(events=events_text)}
],
temperature=0,
max_tokens=15
)
stage = response.choices[0].message.content.strip().lower()
valid = {"discovery", "consideration", "intent", "purchase", "retention"}
return stage if stage in valid else "discovery"
async def process(state: CustomerJourneyState, client: AsyncAzureOpenAI) -> dict:
stage = await classify_stage(state["events"], client)
return {
"journey_stage": stage,
# Signal to orchestrator whether to re-evaluate experiments
"stage_changed": stage != state.get("journey_stage")
}public class JourneyTrackerStep : KernelProcessStep
{
private static readonly string StagePrompt = """
Classify this customer's current journey stage from their recent behavioral events.
Stages:
- discovery: browsing broadly, no repeated product views, no cart activity
- consideration: viewed same product 2+ times OR added to wishlist
- intent: has items in cart, started checkout, or searched for discount codes
- purchase: completed a purchase in the last 30 days
- retention: returning after purchase, browsing accessories
Recent events (newest first, last 10):
{{$events}}
Return ONLY the stage name.
""";
[KernelFunction]
public async Task<JourneyStage> ClassifyStageAsync(
KernelProcessStepContext context,
CustomerJourneyState state,
Kernel kernel)
{
var recent = state.Events.TakeLast(10).Reverse();
var eventsText = string.Join("\n", recent.Select(e =>
$"- {e.Type}: product={e.ProductId ?? "n/a"} at {e.Timestamp:O}"));
var args = new KernelArguments { ["events"] = eventsText };
var result = await kernel.InvokePromptAsync(StagePrompt, args);
var stageText = result.ToString().Trim().ToLower();
var stage = stageText switch
{
"discovery" => JourneyStage.Discovery,
"consideration" => JourneyStage.Consideration,
"intent" => JourneyStage.Intent,
"purchase" => JourneyStage.Purchase,
"retention" => JourneyStage.Retention,
_ => JourneyStage.Discovery
};
bool stageChanged = stage != state.Stage;
state.Stage = stage;
await context.EmitEventAsync(JourneyEvents.TrackComplete,
new TrackResult { Stage = stage, StageChanged = stageChanged });
return stage;
}
}With journey stage classified, the Personalization Agent can apply stage-appropriate content strategies. Here's the content selection logic:
STAGE_CONTENT_STRATEGY = {
"discovery": {
"hero_content": "editorial", # Lifestyle imagery, category highlights
"product_display": "trending", # What's popular right now
"incentive": None, # Don't push an offer yet
"search_suggestion": True, # Prompt discovery via search
},
"consideration": {
"hero_content": "social_proof", # Reviews, ratings, bestseller badges
"product_display": "related", # Items similar to recently viewed
"incentive": "wishlist_reminder", # "Still thinking about X?"
"search_suggestion": False,
},
"intent": {
"hero_content": "urgency", # Limited stock, time-sensitive offer
"product_display": "cart_related", # Cross-sells for items in cart
"incentive": "threshold_offer", # Free shipping or discount trigger
"search_suggestion": False,
},
"purchase": {
"hero_content": "post_purchase", # Order confirmation, tracking
"product_display": "replenishment",# "Time to reorder?" or accessories
"incentive": "loyalty_points", # Reward completion
"search_suggestion": False,
},
"retention": {
"hero_content": "personalized", # Based on purchase history
"product_display": "new_arrivals", # What's new in their categories
"incentive": "loyalty_reward", # Loyalty-tier-specific offer
"search_suggestion": True,
}
}
async def process(state: CustomerJourneyState, search_client, llm_client) -> dict:
stage = state["journey_stage"]
strategy = STAGE_CONTENT_STRATEGY[stage]
# Fetch relevant products from AI Search
search_query = build_search_query(state, strategy)
products = await search_client.search(
search_query,
top=6,
query_type="semantic"
)
return {
"personalization_context": {
"stage": stage,
"strategy": strategy,
"recommended_products": [p async for p in products],
"active_experiments": state["active_experiments"],
}
}public class PersonalizationStep : KernelProcessStep
{
private static readonly Dictionary<JourneyStage, ContentStrategy> StageStrategies = new()
{
[JourneyStage.Discovery] = new ContentStrategy
{
HeroContent = "editorial",
ProductDisplay = "trending",
Incentive = null,
SearchSuggestion = true
},
[JourneyStage.Consideration] = new ContentStrategy
{
HeroContent = "social_proof",
ProductDisplay = "related",
Incentive = "wishlist_reminder",
SearchSuggestion = false
},
[JourneyStage.Intent] = new ContentStrategy
{
HeroContent = "urgency",
ProductDisplay = "cart_related",
Incentive = "threshold_offer",
SearchSuggestion = false
},
[JourneyStage.Purchase] = new ContentStrategy
{
HeroContent = "post_purchase",
ProductDisplay = "replenishment",
Incentive = "loyalty_points",
SearchSuggestion = false
},
[JourneyStage.Retention] = new ContentStrategy
{
HeroContent = "personalized",
ProductDisplay = "new_arrivals",
Incentive = "loyalty_reward",
SearchSuggestion = true
}
};
[KernelFunction]
public async Task PersonalizeAsync(
KernelProcessStepContext context,
CustomerJourneyState state,
SearchClient searchClient)
{
var strategy = StageStrategies[state.Stage];
var searchQuery = BuildSearchQuery(state, strategy);
var searchResults = await searchClient.SearchAsync<ProductDocument>(
searchQuery,
new SearchOptions { Size = 6, QueryType = SearchQueryType.Semantic });
var products = new List<ProductDocument>();
await foreach (var result in searchResults.Value.GetResultsAsync())
products.Add(result.Document);
var personalizationContext = new PersonalizationContext
{
Stage = state.Stage,
Strategy = strategy,
RecommendedProducts = products,
ActiveExperiments = state.ActiveExperiments
};
await context.EmitEventAsync(JourneyEvents.PersonalizationReady, personalizationContext);
}
}ROI & Business Value
The business case for this system rests on three metrics: experiment velocity, conversion lift from stage-aware personalization, and reduction in conflicted experiment cohorts.
| Metric | Before | After | Notes |
|---|---|---|---|
| Experiment conflict rate | ~30% of concurrent tests | <2% | Semantic detection catches what rules miss |
| Time to statistical significance | 14–21 days avg | 7–10 days avg | Cleaner cohorts reduce noise; continuous monitoring |
| Conversion rate (intent-stage visitors) | Baseline | +18–23% lift | From stage-appropriate incentive timing |
| Discovery-stage bounce rate | Baseline | -11% | Removing premature incentive banners |
When This Investment Pays Off
This system makes sense when you have: at least 50,000 monthly active users (enough traffic to reach significance faster), five or more concurrent experiments running at any time (enough for conflicts to matter), and a team capable of interpreting statistical significance correctly. Below these thresholds, a well-maintained rule engine and a single A/B testing tool handle 90% of what this system does at a fraction of the cost.
The frame I use for the conversation with stakeholders: what's the cost of one contaminated experiment? If your typical experiment tests something that, if it works, would lift revenue by 2%, and you run 12 experiments per quarter, a 30% conflict rate means roughly 4 contaminated tests per quarter. If each contaminated test delays a real decision by two weeks and your opportunity cost is $50K in weekly revenue, the conflict problem alone is a $400K annual problem. The AI conflict detection costs roughly $200/month in tokens at steady state.
What's Next
In this first part, I've covered the architecture, the core state model, the experiment conflict detection approach, and the journey-aware personalization strategy. The four agents are independently testable, the orchestrator is event-driven rather than synchronous, and the conflict detection cache means the O(N²) cost only hits you once per experiment pair, not once per customer event.
Part 2 digs into the parts that actually determine whether this gets deployed: real token cost numbers (this system is not free at scale), the observability setup you need to trust the experiment assignments, the Python vs. C# decision for teams choosing a runtime, and — most importantly — an honest look at when you should not build this and use a rules engine instead.
Ready for Part 2?
Part 2 covers production considerations: cost analysis, observability, and when NOT to use this approach.
Read Part 2 →This article demonstrates customer journey orchestration and experiment management concepts. Production code would need error handling, rate limiting, proper state persistence, and compliance review for behavioral tracking.
Want More Practical AI Tutorials?
I write about building production AI systems with Azure, Python, and C#. Subscribe for practical tutorials delivered twice a month.
Subscribe to Newsletter →