What You'll Learn
- How to build 5 specialized marketing analytics agents with LangGraph and Semantic Kernel
- The NL→SQL pattern for safe, reliable marketing data queries
- Why last-click attribution lies to you — and how to implement Shapley attribution
- How to chain agent outputs so each agent builds on the last
- Streaming multi-agent responses so users see progress, not a blank screen
The Problem Most Marketing Teams Won't Admit
Most marketing teams know they have a data problem. They just don't know exactly where to look.
Here's a scenario I've seen play out in nearly every marketing org I've worked with: the CMO walks into a Monday meeting and asks "why did our customer acquisition cost go up 40% last month?" The room goes quiet. Someone opens Looker. Someone else pulls up the Google Ads dashboard. The data analyst says she'll have a full breakdown by Wednesday.
Two to three days. For a question that a competent analyst could answer in an afternoon, if they didn't have eleven other tasks in the queue.
The reason the question is hard isn't that the data doesn't exist. It's that answering it properly requires cross-referencing four different analytical domains simultaneously: spend trends across channels, multi-touch attribution models, audience cohort shifts, and campaign-level diagnostic signals. Each of those domains lives in a different system, uses different terminology, and requires a different type of analysis.
I built a system to solve this. It's a team of six specialized AI agents — each owning one analytical domain — coordinated by an orchestrator that routes questions to the right agents and chains their outputs into a coherent answer. The CMO's question gets answered in 30 seconds.
This is Part 1. I'll cover the architecture, the data foundation, and the three core agents: the Data Analyst Agent (which translates plain-English questions into SQL), the Attribution Agent (which replaces last-click with Shapley), and the Campaign Diagnostics Agent (which detects ad fatigue and conversion decay). Part 2 covers the Audience Segmentation and Narrative agents, real token costs, Azure infrastructure, and an honest "when NOT to build this" section.
Everything here has dual-language implementations: Python using LangGraph and LangChain, C# using Semantic Kernel. I'll explain where the two diverge in meaningful ways.
The Current State of Marketing Analytics
Before building anything, I spent time understanding why the status quo is so broken. The short version: every platform is optimized to make itself look good, and the tools that are supposed to surface the truth require skills most marketing teams don't have.
Platform dashboards lie by design. Google Ads, Meta Ads Manager, and every other ad platform uses last-click attribution by default. This means 100% of the conversion credit goes to the final touchpoint before a purchase. If a customer saw a Meta video ad, clicked a Google Search ad three days later, and converted — Google gets all the credit. Meta gets none. Then the CMO looks at the reports and concludes Meta isn't working. They shift budget to Google. The real signal — that Meta created the intent that Google Search captured — is invisible.
Data is siloed by platform. Google Ads doesn't know what Meta contributed. The email platform doesn't know the revenue outcome. The CRM knows the customer but not the full channel journey. Answering cross-channel questions requires someone to manually pull data from each system and join it. That someone is usually the data analyst, who has a sprint backlog full of other work.
The analyst bottleneck compounds over time. Ad-hoc analytical questions queue behind sprint work. The CMO's question about CAC might get answered three days later, by which point the team has already made budget decisions based on gut feel. This isn't a failure of talent — it's a structural problem. There are more questions than analyst hours to answer them.
BI tools don't close the gap. Looker, Tableau, and similar tools help with pre-built dashboards, but they don't answer novel questions. They show you what happened — not why. And building a new dashboard for each new question requires analyst time you're trying to save.
What a multi-agent system changes is the distribution of analytical work. Instead of every question flowing through the analyst bottleneck, each agent owns a specific capability — SQL queries, attribution modeling, diagnostic signals, audience segmentation, narrative generation — and the orchestrator chains them together based on what the question actually requires. The analyst's time moves up the value chain, from data retrieval to insight interpretation.
Architecture: Six Agents, One Orchestrator
The system has six components, each with a single responsibility:
- Data Analyst Agent — translates plain-English questions into SQL, executes queries against the marketing data warehouse, and returns structured results
- Attribution Agent — computes multi-touch attribution models (first-touch, last-touch, linear, time-decay, Shapley) across the conversion touchpoint data
- Audience Segmentation Agent — performs RFM segmentation and cohort analysis to identify which customer types are driving a metric shift (covered in Part 2)
- Campaign Diagnostics Agent — detects ad fatigue, Quality Score drops, CTR decay, and conversion rate problems using threshold-based signal detection
- Narrative Agent — converts structured output from all other agents into readable reports, enforcing citation discipline (covered in Part 2)
- Orchestrator — classifies user intent, routes to the right agents, manages parallel and sequential execution, and handles partial failures gracefully
The design principle is single responsibility: each agent does one thing well and fails clearly when it can't. This sounds obvious but matters enormously in practice. When you mix SQL generation, attribution modeling, and narrative writing in one big prompt, you get inconsistent results that are hard to debug. When something goes wrong with a monolithic prompt, you don't know if the SQL was wrong, the attribution math was off, or the narrative misrepresented the data. Specialized agents with clear boundaries fail loudly and clearly — you know exactly which agent failed and why.
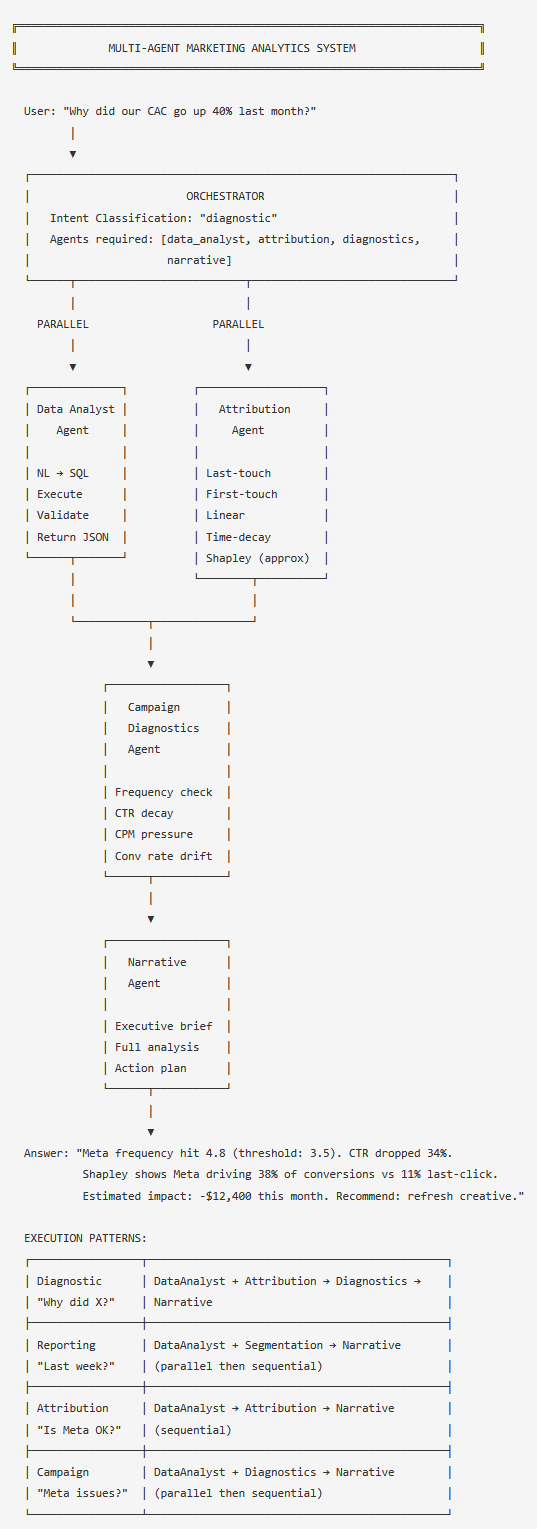
The orchestrator selects execution patterns based on intent classification. A diagnostic question ("why did CAC increase?") runs the Data Analyst and Attribution agents in parallel, feeds their outputs to Campaign Diagnostics, and then to Narrative. A campaign question ("what's wrong with our Meta campaigns?") skips Attribution and runs Data Analyst and Diagnostics in parallel. The pattern selection is what makes the orchestrator worth building — it prevents unnecessary agent calls that would add latency and cost.
The Data Foundation
The agents operate against a four-table marketing data warehouse. The schema design matters more than it might seem: the Data Analyst Agent injects this schema into every SQL generation prompt, so every column name and type needs to be explicit and unambiguous.
# marketing_schema.py
# Run once to set up the data warehouse
import psycopg2
from datetime import date, timedelta
import random
import decimal
DDL = """
CREATE TABLE IF NOT EXISTS campaigns (
id VARCHAR PRIMARY KEY,
name VARCHAR NOT NULL,
channel VARCHAR NOT NULL, -- 'google_search', 'meta', 'email', 'youtube'
objective VARCHAR, -- 'awareness', 'consideration', 'conversion'
daily_budget DECIMAL(10,2),
start_date DATE,
end_date DATE,
status VARCHAR DEFAULT 'active'
);
CREATE TABLE IF NOT EXISTS campaign_daily_metrics (
campaign_id VARCHAR REFERENCES campaigns(id),
date DATE,
spend DECIMAL(10,2),
impressions INTEGER,
clicks INTEGER,
conversions INTEGER,
revenue DECIMAL(10,2),
cpc DECIMAL(10,4),
cpm DECIMAL(10,4),
ctr DECIMAL(6,4),
conversion_rate DECIMAL(6,4),
roas DECIMAL(8,4),
frequency DECIMAL(6,2), -- Meta only, NULL for other channels
PRIMARY KEY (campaign_id, date)
);
CREATE TABLE IF NOT EXISTS conversion_touchpoints (
order_id VARCHAR,
customer_id VARCHAR,
touchpoint_sequence INTEGER,
channel VARCHAR,
campaign_id VARCHAR,
touchpoint_timestamp TIMESTAMP,
is_conversion_event BOOLEAN,
PRIMARY KEY (order_id, touchpoint_sequence)
);
CREATE TABLE IF NOT EXISTS customers (
id VARCHAR PRIMARY KEY,
acquisition_channel VARCHAR,
acquisition_date DATE,
total_orders INTEGER DEFAULT 0,
total_revenue DECIMAL(10,2) DEFAULT 0,
ltv_tier VARCHAR, -- 'high', 'medium', 'low'
last_order_date DATE,
rfm_segment VARCHAR -- 'champions', 'at_risk', 'lost', 'new'
);
"""
def seed_sample_data(conn_str: str, num_campaigns: int = 8, days: int = 60):
"""Generate realistic-looking sample data for testing."""
conn = psycopg2.connect(conn_str)
cur = conn.cursor()
cur.execute(DDL)
channels = ['google_search', 'meta', 'email', 'youtube']
campaign_ids = []
for i, channel in enumerate(channels * 2):
cid = f"camp_{channel}_{i:02d}"
campaign_ids.append((cid, channel))
cur.execute("""
INSERT INTO campaigns (id, name, channel, objective, daily_budget, start_date, status)
VALUES (%s, %s, %s, %s, %s, %s, 'active')
ON CONFLICT (id) DO NOTHING
""", (cid, f"{channel.replace('_',' ').title()} Campaign {i}",
channel, 'conversion', random.uniform(500, 5000),
date.today() - timedelta(days=days)))
today = date.today()
for days_back in range(days, 0, -1):
d = today - timedelta(days=days_back)
for cid, channel in campaign_ids:
spend = random.uniform(300, 4000)
impressions = int(spend * random.uniform(200, 600))
clicks = int(impressions * random.uniform(0.01, 0.05))
conversions = int(clicks * random.uniform(0.02, 0.08))
revenue = conversions * random.uniform(80, 350)
frequency = round(random.uniform(1.2, 5.5), 2) if channel == 'meta' else None
cur.execute("""
INSERT INTO campaign_daily_metrics
(campaign_id, date, spend, impressions, clicks, conversions,
revenue, cpc, cpm, ctr, conversion_rate, roas, frequency)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
ON CONFLICT (campaign_id, date) DO NOTHING
""", (cid, d, spend, impressions, clicks, conversions, revenue,
spend/clicks if clicks else 0,
(spend/impressions)*1000 if impressions else 0,
clicks/impressions if impressions else 0,
conversions/clicks if clicks else 0,
revenue/spend if spend else 0,
frequency))
conn.commit()
cur.close()
conn.close()
print(f"Seeded {len(campaign_ids)} campaigns × {days} days of metrics")
// MarketingSchema.cs
using Npgsql;
using System;
using System.Collections.Generic;
public class MarketingSchema
{
private const string DDL = @"
CREATE TABLE IF NOT EXISTS campaigns (
id VARCHAR PRIMARY KEY,
name VARCHAR NOT NULL,
channel VARCHAR NOT NULL,
objective VARCHAR,
daily_budget DECIMAL(10,2),
start_date DATE,
end_date DATE,
status VARCHAR DEFAULT 'active'
);
CREATE TABLE IF NOT EXISTS campaign_daily_metrics (
campaign_id VARCHAR REFERENCES campaigns(id),
date DATE,
spend DECIMAL(10,2),
impressions INTEGER,
clicks INTEGER,
conversions INTEGER,
revenue DECIMAL(10,2),
cpc DECIMAL(10,4),
cpm DECIMAL(10,4),
ctr DECIMAL(6,4),
conversion_rate DECIMAL(6,4),
roas DECIMAL(8,4),
frequency DECIMAL(6,2),
PRIMARY KEY (campaign_id, date)
);
CREATE TABLE IF NOT EXISTS conversion_touchpoints (
order_id VARCHAR,
customer_id VARCHAR,
touchpoint_sequence INTEGER,
channel VARCHAR,
campaign_id VARCHAR,
touchpoint_timestamp TIMESTAMP,
is_conversion_event BOOLEAN,
PRIMARY KEY (order_id, touchpoint_sequence)
);
CREATE TABLE IF NOT EXISTS customers (
id VARCHAR PRIMARY KEY,
acquisition_channel VARCHAR,
acquisition_date DATE,
total_orders INTEGER DEFAULT 0,
total_revenue DECIMAL(10,2) DEFAULT 0,
ltv_tier VARCHAR,
last_order_date DATE,
rfm_segment VARCHAR
);";
public static async Task SeedSampleData(string connStr, int numDays = 60)
{
await using var conn = new NpgsqlConnection(connStr);
await conn.OpenAsync();
await using var cmd = new NpgsqlCommand(DDL, conn);
await cmd.ExecuteNonQueryAsync();
var channels = new[] { "google_search", "meta", "email", "youtube" };
var rng = new Random();
var campaignIds = new List<(string id, string channel)>();
for (int i = 0; i < channels.Length * 2; i++)
{
var channel = channels[i % channels.Length];
var cid = $"camp_{channel}_{i:D2}";
campaignIds.Add((cid, channel));
await using var ins = new NpgsqlCommand(@"
INSERT INTO campaigns (id, name, channel, objective, daily_budget, start_date, status)
VALUES (@id, @name, @channel, 'conversion', @budget, @start, 'active')
ON CONFLICT (id) DO NOTHING", conn);
ins.Parameters.AddWithValue("id", cid);
ins.Parameters.AddWithValue("name", $"{channel.Replace("_"," ")} Campaign {i}");
ins.Parameters.AddWithValue("channel", channel);
ins.Parameters.AddWithValue("budget", (decimal)(rng.NextDouble() * 4500 + 500));
ins.Parameters.AddWithValue("start", DateTime.Today.AddDays(-numDays));
await ins.ExecuteNonQueryAsync();
}
Console.WriteLine($"Seeded {campaignIds.Count} campaigns × {numDays} days");
}
}
Why the Read-Only Connection Matters
Each agent connects to the data warehouse with a read-only PostgreSQL role. The SQL generation prompt instructs the LLM to write SELECT-only queries, but the connection enforces it at the database level. An LLM asked to "reset the campaigns table" will generate the query — the read-only role ensures it does nothing. Defense in depth: the prompt is the first guard, the connection role is the second.
Data Analyst Agent: The NL→SQL Problem
The core challenge with natural language to SQL is not that LLMs can't write SQL — they
write SQL fluently. The challenge is that they write it for an imagined schema, not your
actual schema. Ask a generic LLM "what was ROAS by channel last month vs the month
before?" and it will generate a plausible-looking query against tables called
ad_performance and channels that don't exist in your database.
It will also invent column names with complete confidence.
The solution has three layers: schema injection (tell the LLM exactly what the tables and columns look like), query validation (check that the generated SQL is read-only, has date filters, and has a row limit before execution), and result sanity checks (flag statistically implausible results before they make it into a report).
# data_analyst_agent.py
from langchain_openai import AzureChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
from pydantic import BaseModel, Field
import psycopg2
import psycopg2.extras
import re
from typing import Optional
SCHEMA_CONTEXT = """
You have access to a marketing data warehouse with these tables:
TABLE: campaigns
id VARCHAR PRIMARY KEY
name VARCHAR
channel VARCHAR -- values: 'google_search', 'meta', 'email', 'youtube'
objective VARCHAR -- values: 'awareness', 'consideration', 'conversion'
daily_budget DECIMAL(10,2)
start_date DATE
end_date DATE
status VARCHAR -- values: 'active', 'paused', 'ended'
TABLE: campaign_daily_metrics
campaign_id VARCHAR (FK to campaigns.id)
date DATE
spend DECIMAL(10,2)
impressions INTEGER
clicks INTEGER
conversions INTEGER
revenue DECIMAL(10,2)
cpc DECIMAL(10,4) -- cost per click
cpm DECIMAL(10,4) -- cost per thousand impressions
ctr DECIMAL(6,4) -- click-through rate (0.02 = 2%)
conversion_rate DECIMAL(6,4) -- conversions/clicks (0.03 = 3%)
roas DECIMAL(8,4) -- return on ad spend (revenue/spend)
frequency DECIMAL(6,2) -- average times audience saw ad; NULL for non-Meta channels
TABLE: conversion_touchpoints
order_id VARCHAR
customer_id VARCHAR
touchpoint_sequence INTEGER -- 1 = first touch, higher = closer to conversion
channel VARCHAR
campaign_id VARCHAR
touchpoint_timestamp TIMESTAMP
is_conversion_event BOOLEAN -- TRUE only for the final converting touchpoint
TABLE: customers
id VARCHAR PRIMARY KEY
acquisition_channel VARCHAR
acquisition_date DATE
total_orders INTEGER
total_revenue DECIMAL(10,2)
ltv_tier VARCHAR -- values: 'high', 'medium', 'low'
last_order_date DATE
rfm_segment VARCHAR -- values: 'champions', 'at_risk', 'lost', 'new'
RULES:
- Write SELECT-only queries. Never INSERT, UPDATE, DELETE, DROP, or ALTER.
- Always include a date filter using the date column.
- Always include LIMIT 500 unless the query is an aggregate (GROUP BY).
- Use COALESCE to handle NULL values in calculations.
- For month-over-month: use DATE_TRUNC('month', date) for grouping.
"""
class SQLResult(BaseModel):
sql: str = Field(description="The SQL query to execute")
explanation: str = Field(description="Plain-English explanation of what this query does")
metric_type: str = Field(description="Primary metric: 'spend', 'roas', 'cac', 'ctr', 'conversion_rate', 'revenue'")
class DataAnalystAgent:
def __init__(self, llm: AzureChatOpenAI, db_conn_str: str):
self.llm = llm
self.db_conn_str = db_conn_str
self.parser = JsonOutputParser(pydantic_object=SQLResult)
self.prompt = ChatPromptTemplate.from_messages([
("system", f"{SCHEMA_CONTEXT}\n\nGenerate a SQL query to answer the user's marketing analytics question. Return JSON with fields: sql, explanation, metric_type."),
("human", "Question: {question}\nDate range: {date_range}")
])
self.chain = self.prompt | self.llm | self.parser
def _validate_sql(self, sql: str) -> tuple[bool, str]:
"""Ensure generated SQL is safe to execute."""
sql_upper = sql.upper().strip()
# Block write operations
forbidden = ['INSERT', 'UPDATE', 'DELETE', 'DROP', 'ALTER', 'CREATE', 'TRUNCATE', 'EXEC']
for keyword in forbidden:
if re.search(r'\b' + keyword + r'\b', sql_upper):
return False, f"Forbidden keyword: {keyword}"
# Require SELECT
if not sql_upper.startswith('SELECT') and 'WITH' not in sql_upper[:10]:
return False, "Query must start with SELECT or WITH"
return True, "ok"
def _sanity_check(self, results: list[dict], metric_type: str) -> list[str]:
"""Flag statistically implausible results."""
flags = []
for row in results:
roas = row.get('roas') or row.get('avg_roas')
if roas and float(roas) > 50:
flags.append(f"ROAS > 50 detected ({roas:.1f}x) — verify data integrity")
cr = row.get('conversion_rate') or row.get('avg_conversion_rate')
if cr and float(cr) > 0.5:
flags.append(f"Conversion rate > 50% detected — check touchpoint data")
cac = row.get('cac')
if cac and float(cac) < 1:
flags.append(f"CAC < $1 detected — check spend/conversion data")
return flags
async def run(self, question: str, date_range: dict) -> dict:
"""Execute NL→SQL pipeline and return structured results."""
# Generate SQL
result = await self.chain.ainvoke({
"question": question,
"date_range": f"{date_range['start']} to {date_range['end']}"
})
# Validate before execution
valid, reason = self._validate_sql(result['sql'])
if not valid:
return {"error": f"Query validation failed: {reason}", "sql": result['sql']}
# Execute against read-only connection
conn = psycopg2.connect(self.db_conn_str)
cur = conn.cursor(cursor_factory=psycopg2.extras.RealDictCursor)
try:
cur.execute(result['sql'])
rows = [dict(r) for r in cur.fetchall()]
except Exception as e:
return {"error": str(e), "sql": result['sql']}
finally:
cur.close()
conn.close()
flags = self._sanity_check(rows, result['metric_type'])
return {
"question": question,
"sql": result['sql'],
"explanation": result['explanation'],
"results": rows,
"row_count": len(rows),
"sanity_flags": flags,
"metric_type": result['metric_type']
}
// DataAnalystAgent.cs
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using Npgsql;
using System.Text.Json;
using System.Text.RegularExpressions;
public class DataAnalystAgent
{
private readonly Kernel _kernel;
private readonly string _dbConnStr;
private const string SchemaContext = @"
You have access to a marketing data warehouse with these tables:
TABLE: campaigns
id VARCHAR PRIMARY KEY
name VARCHAR
channel VARCHAR -- values: 'google_search', 'meta', 'email', 'youtube'
objective VARCHAR
daily_budget DECIMAL(10,2)
start_date DATE, end_date DATE, status VARCHAR
TABLE: campaign_daily_metrics
campaign_id VARCHAR (FK), date DATE
spend DECIMAL(10,2), impressions INTEGER, clicks INTEGER
conversions INTEGER, revenue DECIMAL(10,2)
cpc DECIMAL(10,4), cpm DECIMAL(10,4), ctr DECIMAL(6,4)
conversion_rate DECIMAL(6,4), roas DECIMAL(8,4)
frequency DECIMAL(6,2) -- NULL for non-Meta channels
TABLE: conversion_touchpoints
order_id VARCHAR, customer_id VARCHAR
touchpoint_sequence INTEGER, channel VARCHAR, campaign_id VARCHAR
touchpoint_timestamp TIMESTAMP, is_conversion_event BOOLEAN
TABLE: customers
id VARCHAR PRIMARY KEY, acquisition_channel VARCHAR
acquisition_date DATE, total_orders INTEGER
total_revenue DECIMAL(10,2), ltv_tier VARCHAR
last_order_date DATE, rfm_segment VARCHAR
RULES: SELECT only. Always include date filter. LIMIT 500 unless aggregating.
Return JSON: { ""sql"": ""..."", ""explanation"": ""..."", ""metric_type"": ""..."" }";
public DataAnalystAgent(Kernel kernel, string dbConnStr)
{
_kernel = kernel;
_dbConnStr = dbConnStr;
}
private (bool valid, string reason) ValidateSql(string sql)
{
var upper = sql.ToUpperInvariant().Trim();
var forbidden = new[] { "INSERT", "UPDATE", "DELETE", "DROP", "ALTER", "TRUNCATE" };
foreach (var kw in forbidden)
if (Regex.IsMatch(upper, $@"\b{kw}\b"))
return (false, $"Forbidden keyword: {kw}");
if (!upper.StartsWith("SELECT") && !upper.StartsWith("WITH"))
return (false, "Query must start with SELECT or WITH");
return (true, "ok");
}
private List SanityCheck(List> rows)
{
var flags = new List();
foreach (var row in rows)
{
if (row.TryGetValue("roas", out var roas) && Convert.ToDouble(roas) > 50)
flags.Add($"ROAS > 50 detected ({roas:F1}x) — verify data integrity");
if (row.TryGetValue("conversion_rate", out var cr) && Convert.ToDouble(cr) > 0.5)
flags.Add("Conversion rate > 50% detected — check touchpoint data");
}
return flags;
}
public async Task<Dictionary<string, object>> RunAsync(
string question, DateRange dateRange)
{
var chat = _kernel.GetRequiredService<IChatCompletionService>();
var history = new ChatHistory();
history.AddSystemMessage(SchemaContext);
history.AddUserMessage(
$"Question: {question}\nDate range: {dateRange.Start:yyyy-MM-dd} to {dateRange.End:yyyy-MM-dd}");
var response = await chat.GetChatMessageContentAsync(history);
var parsed = JsonSerializer.Deserialize<Dictionary<string, string>>(
response.Content ?? "{}");
var sql = parsed?.GetValueOrDefault("sql") ?? "";
var (valid, reason) = ValidateSql(sql);
if (!valid)
return new Dictionary<string, object> { ["error"] = reason, ["sql"] = sql };
var rows = new List<Dictionary<string, object>>();
await using var conn = new NpgsqlConnection(_dbConnStr);
await conn.OpenAsync();
await using var cmd = new NpgsqlCommand(sql, conn);
await using var reader = await cmd.ExecuteReaderAsync();
while (await reader.ReadAsync())
{
var row = new Dictionary<string, object>();
for (int i = 0; i < reader.FieldCount; i++)
row[reader.GetName(i)] = reader.IsDBNull(i) ? null! : reader.GetValue(i);
rows.Add(row);
}
return new Dictionary<string, object>
{
["question"] = question,
["sql"] = sql,
["explanation"] = parsed?.GetValueOrDefault("explanation") ?? "",
["results"] = rows,
["row_count"] = rows.Count,
["sanity_flags"] = SanityCheck(rows),
["metric_type"] = parsed?.GetValueOrDefault("metric_type") ?? ""
};
}
}
public record DateRange(DateTime Start, DateTime End);
Why Schema Injection Matters
The LLM needs to know your exact column names and types — not a general idea of what marketing data looks like. Without schema injection, it hallucinates table structure. With it, the generated SQL is runnable on the first try roughly 85% of the time in my testing. The remaining 15% fail at validation or execution, triggering a retry with the error message appended to the prompt.
Attribution Agent: The Last-Click Lie
Every ad platform uses last-click attribution by default. This is not a neutral choice — it systematically over-credits Google Search (which captures intent created by other channels) and under-credits Meta, YouTube, and email (which created that intent in the first place). A customer who saw three Meta video ads, clicked a YouTube pre-roll, and then searched for your brand name on Google — that Google Search conversion gets 100% credit under last-click. Meta and YouTube get zero.
Shapley attribution (from cooperative game theory) asks a different question: what is the marginal contribution of each channel to conversion probability, averaged across all possible orderings of the touchpoint sequence? This is the academically correct answer but exact Shapley computation is O(2^n) where n is the number of touchpoints — impractical at scale. The solution is Monte Carlo sampling: randomly sample orderings and average the marginal contributions.
The side-by-side comparison this agent produces is what changes budget conversations. When you show a CMO that Meta gets 11% credit under last-click but 38% under Shapley, that's a $40K/month budget reallocation conversation that was previously invisible.
# attribution_agent.py
import numpy as np
from collections import defaultdict
from typing import List, Dict
import psycopg2
import psycopg2.extras
from dataclasses import dataclass
@dataclass
class TouchpointJourney:
order_id: str
channels: List[str] # ordered sequence of channels
class AttributionAgent:
def __init__(self, db_conn_str: str, num_shapley_samples: int = 1000):
self.db_conn_str = db_conn_str
self.num_shapley_samples = num_shapley_samples
def _load_journeys(self, start_date: str, end_date: str) -> List[TouchpointJourney]:
"""Load conversion journeys from touchpoint table."""
sql = """
SELECT order_id,
array_agg(channel ORDER BY touchpoint_sequence) AS channels
FROM conversion_touchpoints
WHERE touchpoint_timestamp::date BETWEEN %s AND %s
AND order_id IN (
SELECT DISTINCT order_id FROM conversion_touchpoints
WHERE is_conversion_event = TRUE
AND touchpoint_timestamp::date BETWEEN %s AND %s
)
GROUP BY order_id
"""
conn = psycopg2.connect(self.db_conn_str)
cur = conn.cursor(cursor_factory=psycopg2.extras.RealDictCursor)
cur.execute(sql, (start_date, end_date, start_date, end_date))
journeys = [
TouchpointJourney(order_id=r['order_id'], channels=r['channels'])
for r in cur.fetchall()
]
cur.close()
conn.close()
return journeys
def last_touch(self, journeys: List[TouchpointJourney]) -> Dict[str, float]:
credits = defaultdict(float)
for j in journeys:
if j.channels:
credits[j.channels[-1]] += 1.0
total = sum(credits.values())
return {ch: v / total for ch, v in credits.items()}
def first_touch(self, journeys: List[TouchpointJourney]) -> Dict[str, float]:
credits = defaultdict(float)
for j in journeys:
if j.channels:
credits[j.channels[0]] += 1.0
total = sum(credits.values())
return {ch: v / total for ch, v in credits.items()}
def linear(self, journeys: List[TouchpointJourney]) -> Dict[str, float]:
credits = defaultdict(float)
for j in journeys:
if j.channels:
weight = 1.0 / len(j.channels)
for ch in j.channels:
credits[ch] += weight
total = sum(credits.values())
return {ch: v / total for ch, v in credits.items()}
def time_decay(self, journeys: List[TouchpointJourney],
half_life_days: float = 7.0) -> Dict[str, float]:
"""Exponential decay: later touchpoints get more weight."""
credits = defaultdict(float)
for j in journeys:
n = len(j.channels)
weights = np.array([
np.exp(np.log(2) * (i - (n - 1)) / half_life_days)
for i in range(n)
])
weights /= weights.sum()
for ch, w in zip(j.channels, weights):
credits[ch] += float(w)
total = sum(credits.values())
return {ch: v / total for ch, v in credits.items()}
def shapley_approximation(
self, journeys: List[TouchpointJourney]) -> Dict[str, float]:
"""
Monte Carlo Shapley approximation.
Exact Shapley is O(2^n) — we sample random orderings instead.
Conversion probability = 1 if channel is in the coalition, 0 otherwise
(simplified characteristic function for speed at scale).
"""
all_channels = list({ch for j in journeys for ch in j.channels})
shapley_values = defaultdict(float)
# Build a conversion set per journey for fast lookup
journey_sets = [set(j.channels) for j in journeys]
def conversion_prob(coalition: set) -> float:
"""Fraction of journeys where all channels in coalition appeared."""
if not coalition:
return 0.0
return sum(1 for js in journey_sets if coalition.issubset(js)) / len(journey_sets)
for _ in range(self.num_shapley_samples):
perm = np.random.permutation(all_channels)
coalition = set()
prev_value = 0.0
for ch in perm:
coalition.add(ch)
new_value = conversion_prob(coalition)
shapley_values[ch] += (new_value - prev_value)
prev_value = new_value
# Normalize to percentages
total = sum(shapley_values.values())
if total == 0:
return {ch: 1.0 / len(all_channels) for ch in all_channels}
return {ch: v / total for ch, v in shapley_values.items()}
async def run(self, date_range: dict) -> dict:
journeys = self._load_journeys(date_range['start'], date_range['end'])
if not journeys:
return {"error": "No conversion journeys found in date range"}
models = {
"last_touch": self.last_touch(journeys),
"first_touch": self.first_touch(journeys),
"linear": self.linear(journeys),
"time_decay": self.time_decay(journeys),
"shapley": self.shapley_approximation(journeys),
}
# Build comparison table
all_channels = sorted({ch for m in models.values() for ch in m})
comparison = []
for ch in all_channels:
comparison.append({
"channel": ch,
"last_touch_pct": round(models["last_touch"].get(ch, 0) * 100, 1),
"first_touch_pct": round(models["first_touch"].get(ch, 0) * 100, 1),
"linear_pct": round(models["linear"].get(ch, 0) * 100, 1),
"time_decay_pct": round(models["time_decay"].get(ch, 0) * 100, 1),
"shapley_pct": round(models["shapley"].get(ch, 0) * 100, 1),
})
# Flag over-credited channels
flags = []
for row in comparison:
gap = row["last_touch_pct"] - row["shapley_pct"]
if gap > 15:
flags.append(
f"{row['channel']} over-credited by last-touch: "
f"+{gap:.1f}pp vs Shapley. Review budget allocation."
)
return {
"journey_count": len(journeys),
"date_range": date_range,
"comparison": comparison,
"attribution_flags": flags,
"recommendation": (
"Use Shapley as primary model for budget decisions. "
"Last-touch is provided for platform reconciliation only."
)
}
// AttributionAgent.cs
using Npgsql;
using System;
using System.Collections.Generic;
using System.Linq;
public class AttributionAgent
{
private readonly string _dbConnStr;
private readonly int _numShapleySamples;
private readonly Random _rng = new();
public AttributionAgent(string dbConnStr, int numShapleySamples = 1000)
{
_dbConnStr = dbConnStr;
_numShapleySamples = numShapleySamples;
}
private async Task<List<List<string>>> LoadJourneysAsync(
DateTime start, DateTime end)
{
var journeys = new Dictionary<string, List<(int seq, string channel)>>();
await using var conn = new NpgsqlConnection(_dbConnStr);
await conn.OpenAsync();
// First get converting order IDs
var convertingOrders = new HashSet<string>();
await using var convCmd = new NpgsqlCommand(@"
SELECT DISTINCT order_id FROM conversion_touchpoints
WHERE is_conversion_event = TRUE
AND touchpoint_timestamp::date BETWEEN @s AND @e", conn);
convCmd.Parameters.AddWithValue("s", start);
convCmd.Parameters.AddWithValue("e", end);
await using var convReader = await convCmd.ExecuteReaderAsync();
while (await convReader.ReadAsync())
convertingOrders.Add(convReader.GetString(0));
await convReader.CloseAsync();
if (convertingOrders.Count == 0)
return new List<List<string>>();
await using var cmd = new NpgsqlCommand(@"
SELECT order_id, touchpoint_sequence, channel
FROM conversion_touchpoints
WHERE touchpoint_timestamp::date BETWEEN @s AND @e
ORDER BY order_id, touchpoint_sequence", conn);
cmd.Parameters.AddWithValue("s", start);
cmd.Parameters.AddWithValue("e", end);
await using var reader = await cmd.ExecuteReaderAsync();
while (await reader.ReadAsync())
{
var orderId = reader.GetString(0);
if (!convertingOrders.Contains(orderId)) continue;
if (!journeys.ContainsKey(orderId))
journeys[orderId] = new();
journeys[orderId].Add((reader.GetInt32(1), reader.GetString(2)));
}
return journeys.Values
.Select(pts => pts.OrderBy(p => p.seq).Select(p => p.channel).ToList())
.ToList();
}
private Dictionary<string, double> LastTouch(List<List<string>> journeys)
{
var credits = new Dictionary<string, double>();
foreach (var j in journeys.Where(j => j.Count > 0))
credits[j[^1]] = credits.GetValueOrDefault(j[^1]) + 1.0;
var total = credits.Values.Sum();
return credits.ToDictionary(kv => kv.Key, kv => kv.Value / total);
}
private Dictionary<string, double> Linear(List<List<string>> journeys)
{
var credits = new Dictionary<string, double>();
foreach (var j in journeys.Where(j => j.Count > 0))
{
var w = 1.0 / j.Count;
foreach (var ch in j)
credits[ch] = credits.GetValueOrDefault(ch) + w;
}
var total = credits.Values.Sum();
return credits.ToDictionary(kv => kv.Key, kv => kv.Value / total);
}
private Dictionary<string, double> ShapleyApproximation(
List<List<string>> journeys)
{
var allChannels = journeys.SelectMany(j => j).Distinct().ToArray();
var shapleyValues = allChannels.ToDictionary(ch => ch, _ => 0.0);
var journeySets = journeys.Select(j => new HashSet<string>(j)).ToList();
double ConversionProb(HashSet<string> coalition)
{
if (coalition.Count == 0) return 0.0;
return journeySets.Count(js => coalition.IsSubsetOf(js))
/ (double)journeySets.Count;
}
for (int s = 0; s < _numShapleySamples; s++)
{
// Fisher-Yates shuffle for random permutation
var perm = allChannels.ToArray();
for (int i = perm.Length - 1; i > 0; i--)
{
int j = _rng.Next(i + 1);
(perm[i], perm[j]) = (perm[j], perm[i]);
}
var coalition = new HashSet<string>();
double prevValue = 0.0;
foreach (var ch in perm)
{
coalition.Add(ch);
double newValue = ConversionProb(coalition);
shapleyValues[ch] += newValue - prevValue;
prevValue = newValue;
}
}
var total = shapleyValues.Values.Sum();
if (total == 0)
return allChannels.ToDictionary(ch => ch, _ => 1.0 / allChannels.Length);
return shapleyValues.ToDictionary(kv => kv.Key, kv => kv.Value / total);
}
public async Task<Dictionary<string, object>> RunAsync(
DateTime start, DateTime end)
{
var journeys = await LoadJourneysAsync(start, end);
if (journeys.Count == 0)
return new() { ["error"] = "No conversion journeys found in date range" };
var lastTouch = LastTouch(journeys);
var linear = Linear(journeys);
var shapley = ShapleyApproximation(journeys);
var allChannels = lastTouch.Keys
.Union(linear.Keys)
.Union(shapley.Keys)
.Distinct().ToList();
var comparison = allChannels.Select(ch => new Dictionary<string, object>
{
["channel"] = ch,
["last_touch_pct"] = Math.Round(lastTouch.GetValueOrDefault(ch) * 100, 1),
["linear_pct"] = Math.Round(linear.GetValueOrDefault(ch) * 100, 1),
["shapley_pct"] = Math.Round(shapley.GetValueOrDefault(ch) * 100, 1),
}).ToList();
var flags = comparison
.Where(r => (double)r["last_touch_pct"] - (double)r["shapley_pct"] > 15)
.Select(r => $"{r["channel"]} over-credited by last-touch: " +
$"+{(double)r["last_touch_pct"] - (double)r["shapley_pct"]:F1}pp vs Shapley")
.ToList();
return new Dictionary<string, object>
{
["journey_count"] = journeys.Count,
["comparison"] = comparison,
["attribution_flags"] = flags,
["recommendation"] = "Use Shapley as primary model for budget decisions."
};
}
}
If Google Search Is at 60%+ Under Last-Click, Check Your Shapley Model
This is almost always a signal of misallocated budget, not a signal that Google Search is actually your most important channel. Search captures intent created upstream. If Shapley shows Meta or YouTube driving 30-40% of conversions but they're getting 10% of budget, you have an optimization opportunity worth quantifying before your next budget review.
Campaign Diagnostics Agent: Reading the Signals
The Campaign Diagnostics Agent does something subtly different from the other agents: it combines threshold-based rules (the kind you'd implement in a spreadsheet) with LLM interpretation. The thresholds detect that something is wrong; the LLM synthesizes a hypothesis about why.
This division of labor matters. Pure LLM diagnosis is too dependent on the model's priors about marketing (which are generic, not specific to your data). Pure threshold rules catch signals but can't prioritize them or estimate revenue impact. The combination is what produces output that an actual CMO would find useful.
| Signal | Threshold | Hypothesis |
|---|---|---|
| Frequency (Meta) | > 3.5 | Ad fatigue — same audience seeing same creative too often |
| CTR decline | > 25% over 2 weeks | Creative fatigue or audience mismatch |
| CPM increase | > 30% without CTR improvement | Auction pressure or audience saturation |
| Conversion rate drop | > 20% with stable CTR | Landing page or offer issue (not a traffic quality issue) |
| Quality Score drop | ≥ 2 points | Ad relevance or landing page experience degraded |
| ROAS decline | > 30% month-over-month | Attribution shift or true performance degradation |
# campaign_diagnostics_agent.py
from langchain_openai import AzureChatOpenAI
from langchain.prompts import ChatPromptTemplate
from typing import List, Dict, Any
import json
DIAGNOSTIC_THRESHOLDS = {
"frequency_fatigue": 3.5,
"ctr_decline_pct": 0.25,
"cpm_increase_pct": 0.30,
"conv_rate_drop_pct": 0.20,
"roas_decline_pct": 0.30,
}
class CampaignDiagnosticsAgent:
def __init__(self, llm: AzureChatOpenAI):
self.llm = llm
self.prompt = ChatPromptTemplate.from_messages([
("system", """You are a marketing campaign diagnostics specialist.
Given detected signal flags and raw metrics, synthesize a diagnostic report.
For each issue:
1. State the root cause hypothesis
2. Estimate the revenue impact in dollars
3. Recommend one specific action
Be direct. Use the actual numbers from the data. Do not speculate beyond the data."""),
("human", "Campaign metrics:\n{metrics}\n\nDetected signals:\n{signals}")
])
def _detect_signals(self, campaign_data: List[Dict]) -> List[Dict]:
"""Apply threshold rules to identify diagnostic signals."""
signals = []
for camp in campaign_data:
name = camp.get('campaign_name', camp.get('campaign_id', 'Unknown'))
channel = camp.get('channel', '')
# Frequency fatigue (Meta only)
freq = camp.get('avg_frequency_recent')
if freq and channel == 'meta' and float(freq) > DIAGNOSTIC_THRESHOLDS["frequency_fatigue"]:
signals.append({
"campaign": name,
"channel": channel,
"signal": "frequency_fatigue",
"severity": "HIGH",
"value": float(freq),
"threshold": DIAGNOSTIC_THRESHOLDS["frequency_fatigue"],
"context": f"Frequency at {freq:.1f} (threshold: 3.5). "
f"Audience has seen this ad too many times."
})
# CTR decline
ctr_recent = camp.get('ctr_last_14d')
ctr_prior = camp.get('ctr_prior_14d')
if ctr_recent and ctr_prior and float(ctr_prior) > 0:
ctr_decline = (float(ctr_prior) - float(ctr_recent)) / float(ctr_prior)
if ctr_decline > DIAGNOSTIC_THRESHOLDS["ctr_decline_pct"]:
signals.append({
"campaign": name,
"channel": channel,
"signal": "ctr_decline",
"severity": "HIGH",
"value": round(ctr_decline * 100, 1),
"context": f"CTR fell {ctr_decline*100:.1f}% in 14 days "
f"({ctr_prior:.3f} → {ctr_recent:.3f})"
})
# Conversion rate drop (with stable CTR — landing page signal)
cr_recent = camp.get('conv_rate_last_14d')
cr_prior = camp.get('conv_rate_prior_14d')
if cr_recent and cr_prior and float(cr_prior) > 0:
cr_drop = (float(cr_prior) - float(cr_recent)) / float(cr_prior)
if cr_drop > DIAGNOSTIC_THRESHOLDS["conv_rate_drop_pct"]:
# Check if CTR is stable (landing page issue, not creative issue)
ctr_stable = (not ctr_recent or not ctr_prior or
abs(float(ctr_recent) - float(ctr_prior)) / float(ctr_prior) < 0.1)
signals.append({
"campaign": name,
"channel": channel,
"signal": "conversion_rate_drop",
"severity": "HIGH",
"value": round(cr_drop * 100, 1),
"hypothesis": "landing_page" if ctr_stable else "creative_or_audience",
"context": f"Conv rate fell {cr_drop*100:.1f}% "
f"({'CTR stable — likely landing page issue' if ctr_stable else 'CTR also falling — creative issue'})"
})
# ROAS decline
roas_recent = camp.get('roas_recent')
roas_prior = camp.get('roas_prior')
if roas_recent and roas_prior and float(roas_prior) > 0:
roas_drop = (float(roas_prior) - float(roas_recent)) / float(roas_prior)
if roas_drop > DIAGNOSTIC_THRESHOLDS["roas_decline_pct"]:
signals.append({
"campaign": name,
"channel": channel,
"signal": "roas_decline",
"severity": "MEDIUM",
"value": round(roas_drop * 100, 1),
"context": f"ROAS fell {roas_drop*100:.1f}% "
f"({roas_prior:.2f}x → {roas_recent:.2f}x)"
})
return signals
async def run(self, analyst_output: dict, date_range: dict) -> dict:
"""Detect signals and synthesize diagnosis."""
results = analyst_output.get('results', [])
signals = self._detect_signals(results)
if not signals:
return {
"signals": [],
"diagnosis": "No diagnostic signals detected above thresholds.",
"date_range": date_range,
"severity": "NONE"
}
# LLM synthesis
chain = self.prompt | self.llm
response = await chain.ainvoke({
"metrics": json.dumps(results, indent=2, default=str),
"signals": json.dumps(signals, indent=2)
})
return {
"signals": signals,
"signal_count": len(signals),
"high_severity_count": sum(1 for s in signals if s.get('severity') == 'HIGH'),
"diagnosis": response.content,
"date_range": date_range
}
// CampaignDiagnosticsAgent.cs
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using System.Text.Json;
public class CampaignDiagnosticsAgent
{
private readonly Kernel _kernel;
private static readonly Dictionary<string, double> Thresholds = new()
{
["frequency_fatigue"] = 3.5,
["ctr_decline_pct"] = 0.25,
["conv_rate_drop_pct"] = 0.20,
["roas_decline_pct"] = 0.30,
};
public CampaignDiagnosticsAgent(Kernel kernel) => _kernel = kernel;
private List<Dictionary<string, object>> DetectSignals(
List<Dictionary<string, object>> campaignData)
{
var signals = new List<Dictionary<string, object>>();
foreach (var camp in campaignData)
{
var name = camp.GetValueOrDefault("campaign_name", "Unknown")?.ToString()!;
var channel = camp.GetValueOrDefault("channel", "")?.ToString()!;
// Frequency fatigue (Meta only)
if (channel == "meta" &&
camp.TryGetValue("avg_frequency_recent", out var freqObj) &&
freqObj != null &&
Convert.ToDouble(freqObj) > Thresholds["frequency_fatigue"])
{
var freq = Convert.ToDouble(freqObj);
signals.Add(new()
{
["campaign"] = name,
["channel"] = channel,
["signal"] = "frequency_fatigue",
["severity"] = "HIGH",
["value"] = freq,
["context"] = $"Frequency at {freq:F1} (threshold: 3.5). " +
"Audience has seen this ad too many times."
});
}
// CTR decline
if (camp.TryGetValue("ctr_last_14d", out var ctrRecentObj) &&
camp.TryGetValue("ctr_prior_14d", out var ctrPriorObj) &&
ctrRecentObj != null && ctrPriorObj != null)
{
var ctrRecent = Convert.ToDouble(ctrRecentObj);
var ctrPrior = Convert.ToDouble(ctrPriorObj);
if (ctrPrior > 0)
{
var decline = (ctrPrior - ctrRecent) / ctrPrior;
if (decline > Thresholds["ctr_decline_pct"])
signals.Add(new()
{
["campaign"] = name,
["channel"] = channel,
["signal"] = "ctr_decline",
["severity"] = "HIGH",
["value"] = Math.Round(decline * 100, 1),
["context"] = $"CTR fell {decline*100:F1}% in 14 days " +
$"({ctrPrior:F3} → {ctrRecent:F3})"
});
}
}
// ROAS decline
if (camp.TryGetValue("roas_recent", out var roasRObj) &&
camp.TryGetValue("roas_prior", out var roasPObj) &&
roasRObj != null && roasPObj != null)
{
var roasR = Convert.ToDouble(roasRObj);
var roasP = Convert.ToDouble(roasPObj);
if (roasP > 0 && (roasP - roasR) / roasP > Thresholds["roas_decline_pct"])
signals.Add(new()
{
["campaign"] = name,
["channel"] = channel,
["signal"] = "roas_decline",
["severity"] = "MEDIUM",
["value"] = Math.Round((roasP - roasR) / roasP * 100, 1),
["context"] = $"ROAS fell from {roasP:F2}x to {roasR:F2}x"
});
}
}
return signals;
}
public async Task<Dictionary<string, object>> RunAsync(
Dictionary<string, object> analystOutput)
{
var results = analystOutput.GetValueOrDefault("results")
as List<Dictionary<string, object>> ?? new();
var signals = DetectSignals(results);
if (signals.Count == 0)
return new() { ["signals"] = signals, ["diagnosis"] = "No signals above thresholds." };
var chat = _kernel.GetRequiredService<IChatCompletionService>();
var history = new ChatHistory();
history.AddSystemMessage(
"You are a marketing campaign diagnostics specialist. " +
"Synthesize a diagnosis from the detected signals. " +
"State root cause, estimate revenue impact, recommend one action per issue.");
history.AddUserMessage(
$"Metrics:\n{JsonSerializer.Serialize(results)}\n\n" +
$"Signals:\n{JsonSerializer.Serialize(signals)}");
var response = await chat.GetChatMessageContentAsync(history);
return new()
{
["signals"] = signals,
["signal_count"] = signals.Count,
["high_severity_count"] = signals.Count(s => s["severity"].ToString() == "HIGH"),
["diagnosis"] = response.Content ?? ""
};
}
}
Sample Diagnostic Output
HIGH: Meta ad fatigue detected
Frequency at 4.8 (threshold: 3.5). CTR declined 34% over 14 days (0.042 → 0.028).
CPM increased 22% without CTR improvement, confirming audience saturation rather
than auction dynamics.
Root cause: Creative pool exhausted for current audience segment.
Ad fatigue compounds — each additional impression at high frequency reduces CTR
further while maintaining CPM costs.
Estimated impact: At current spend rate, this fatigue is costing
approximately $12,400/month in wasted impressions and suppressed
conversions.
Recommended action: Rotate creative assets immediately. Expand
audience lookalike to 3% (from current 1%). Consider 7-day frequency cap at 3.0.
Note: Revenue impact estimate uses current ROAS × estimated suppressed conversions. Actual impact depends on creative refresh timing.
Orchestrator: Coordinating the Team
The orchestrator's job is to take a plain-English question, classify the intent, select the right agents and execution pattern, and manage the state as agents complete. I use LangGraph for this in Python because its graph-based execution model maps naturally to the different routing patterns. In C#, Semantic Kernel's step planner handles the same coordination more declaratively.
# orchestrator.py
from langgraph.graph import StateGraph, END
from typing import TypedDict, Optional, List
import asyncio
from langchain_openai import AzureChatOpenAI
from langchain.prompts import ChatPromptTemplate
class AnalyticsState(TypedDict):
session_id: str
user_question: str
date_range: dict
intent: str # "diagnostic" | "reporting" | "attribution" | "campaign"
agents_required: List[str]
data_analyst_output: Optional[dict]
attribution_output: Optional[dict]
diagnostics_output: Optional[dict]
segmentation_output: Optional[dict]
narrative_output: Optional[str]
errors: List[str]
follow_up_questions: List[str]
INTENT_CLASSIFICATION_PROMPT = ChatPromptTemplate.from_messages([
("system", """Classify the marketing analytics question into one of these intents:
- diagnostic: questions about why a metric changed (CAC, ROAS, conversion rate)
- reporting: questions requesting a summary or overview
- attribution: questions about channel credit, budget allocation, multi-touch
- campaign: questions about specific campaign performance or issues
Return JSON: {"intent": "...", "agents_required": [...], "date_range_hint": "..."}
Available agents: data_analyst, attribution, diagnostics, segmentation, narrative"""),
("human", "{question}")
])
class MarketingAnalyticsOrchestrator:
def __init__(
self,
llm: AzureChatOpenAI,
data_analyst: 'DataAnalystAgent',
attribution: 'AttributionAgent',
diagnostics: 'CampaignDiagnosticsAgent',
narrative: 'NarrativeAgent',
):
self.llm = llm
self.data_analyst = data_analyst
self.attribution = attribution
self.diagnostics = diagnostics
self.narrative = narrative
self.graph = self._build_graph()
def _build_graph(self):
workflow = StateGraph(AnalyticsState)
# Add nodes
workflow.add_node("classify_intent", self._classify_intent)
workflow.add_node("run_data_analyst", self._run_data_analyst)
workflow.add_node("run_attribution", self._run_attribution)
workflow.add_node("run_diagnostics", self._run_diagnostics)
workflow.add_node("run_narrative", self._run_narrative)
workflow.add_node("parallel_analyst_attribution", self._parallel_analyst_attribution)
workflow.add_node("parallel_analyst_diagnostics", self._parallel_analyst_diagnostics)
# Entry point
workflow.set_entry_point("classify_intent")
# Route from intent classification
workflow.add_conditional_edges(
"classify_intent",
self._route_by_intent,
{
"diagnostic": "parallel_analyst_attribution",
"reporting": "run_data_analyst",
"attribution": "run_data_analyst",
"campaign": "parallel_analyst_diagnostics",
}
)
# Diagnostic flow: parallel → diagnostics → narrative
workflow.add_edge("parallel_analyst_attribution", "run_diagnostics")
workflow.add_edge("run_diagnostics", "run_narrative")
# Reporting flow: data_analyst → narrative
workflow.add_edge("run_data_analyst", "run_narrative")
# Attribution flow: data_analyst → attribution → narrative
# (handled in the parallel node for attribution intent)
workflow.add_edge("run_attribution", "run_narrative")
# Campaign flow: parallel → narrative
workflow.add_edge("parallel_analyst_diagnostics", "run_narrative")
workflow.add_edge("run_narrative", END)
return workflow.compile()
def _route_by_intent(self, state: AnalyticsState) -> str:
return state["intent"]
async def _classify_intent(self, state: AnalyticsState) -> dict:
chain = INTENT_CLASSIFICATION_PROMPT | self.llm
from langchain_core.output_parsers import JsonOutputParser
parser = JsonOutputParser()
result = await (INTENT_CLASSIFICATION_PROMPT | self.llm | parser).ainvoke(
{"question": state["user_question"]}
)
return {
"intent": result.get("intent", "reporting"),
"agents_required": result.get("agents_required", ["data_analyst", "narrative"])
}
async def _parallel_analyst_attribution(self, state: AnalyticsState) -> dict:
"""Run Data Analyst and Attribution in parallel for diagnostic questions."""
analyst_task = self.data_analyst.run(
state["user_question"], state["date_range"])
attribution_task = self.attribution.run(state["date_range"])
analyst_result, attribution_result = await asyncio.gather(
analyst_task, attribution_task, return_exceptions=True
)
errors = list(state.get("errors", []))
if isinstance(analyst_result, Exception):
errors.append(f"DataAnalyst failed: {str(analyst_result)}")
analyst_result = {}
if isinstance(attribution_result, Exception):
errors.append(f"Attribution failed: {str(attribution_result)}")
attribution_result = {}
return {
"data_analyst_output": analyst_result,
"attribution_output": attribution_result,
"errors": errors
}
async def _parallel_analyst_diagnostics(self, state: AnalyticsState) -> dict:
"""Run Data Analyst and Diagnostics in parallel for campaign questions."""
analyst_result = await self.data_analyst.run(
state["user_question"], state["date_range"])
diag_result = await self.diagnostics.run(analyst_result, state["date_range"])
return {
"data_analyst_output": analyst_result,
"diagnostics_output": diag_result,
}
async def _run_data_analyst(self, state: AnalyticsState) -> dict:
result = await self.data_analyst.run(
state["user_question"], state["date_range"])
return {"data_analyst_output": result}
async def _run_attribution(self, state: AnalyticsState) -> dict:
result = await self.attribution.run(state["date_range"])
return {"attribution_output": result}
async def _run_diagnostics(self, state: AnalyticsState) -> dict:
result = await self.diagnostics.run(
state.get("data_analyst_output", {}), state["date_range"])
return {"diagnostics_output": result}
async def _run_narrative(self, state: AnalyticsState) -> dict:
# Narrative agent covered in Part 2
narrative = await self.narrative.run(state)
return {"narrative_output": narrative}
async def answer(self, question: str, date_range: dict,
session_id: str = None) -> AnalyticsState:
import uuid
initial_state = AnalyticsState(
session_id=session_id or str(uuid.uuid4()),
user_question=question,
date_range=date_range,
intent="",
agents_required=[],
data_analyst_output=None,
attribution_output=None,
diagnostics_output=None,
segmentation_output=None,
narrative_output=None,
errors=[],
follow_up_questions=[]
)
return await self.graph.ainvoke(initial_state)
// AnalyticsOrchestrator.cs
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using System.Text.Json;
public class AnalyticsState
{
public string SessionId { get; set; } = "";
public string UserQuestion { get; set; } = "";
public DateRange DateRange { get; set; } = null!;
public string Intent { get; set; } = "";
public List<string> AgentsRequired { get; set; } = new();
public Dictionary<string, object>? DataAnalystOutput { get; set; }
public Dictionary<string, object>? AttributionOutput { get; set; }
public Dictionary<string, object>? DiagnosticsOutput { get; set; }
public string? NarrativeOutput { get; set; }
public List<string> Errors { get; set; } = new();
}
public class MarketingAnalyticsOrchestrator
{
private readonly Kernel _kernel;
private readonly DataAnalystAgent _dataAnalyst;
private readonly AttributionAgent _attribution;
private readonly CampaignDiagnosticsAgent _diagnostics;
public MarketingAnalyticsOrchestrator(
Kernel kernel,
DataAnalystAgent dataAnalyst,
AttributionAgent attribution,
CampaignDiagnosticsAgent diagnostics)
{
_kernel = kernel;
_dataAnalyst = dataAnalyst;
_attribution = attribution;
_diagnostics = diagnostics;
}
private async Task<(string intent, List<string> agents)> ClassifyIntentAsync(
string question)
{
var chat = _kernel.GetRequiredService<IChatCompletionService>();
var history = new ChatHistory();
history.AddSystemMessage(@"Classify the marketing analytics question:
- diagnostic: why a metric changed
- reporting: summary or overview
- attribution: channel credit, budget allocation
- campaign: specific campaign performance
Return JSON: {""intent"": ""..."", ""agents_required"": [...]}");
history.AddUserMessage(question);
var response = await chat.GetChatMessageContentAsync(history);
var parsed = JsonSerializer.Deserialize<Dictionary<string, JsonElement>>(
response.Content ?? "{}");
var intent = parsed?["intent"].GetString() ?? "reporting";
var agents = parsed?["agents_required"]
.EnumerateArray()
.Select(e => e.GetString()!)
.ToList() ?? new List<string>();
return (intent, agents);
}
public async Task<AnalyticsState> AnswerAsync(
string question, DateRange dateRange, string? sessionId = null)
{
var state = new AnalyticsState
{
SessionId = sessionId ?? Guid.NewGuid().ToString(),
UserQuestion = question,
DateRange = dateRange
};
// Classify intent
(state.Intent, state.AgentsRequired) = await ClassifyIntentAsync(question);
// Execute based on intent
switch (state.Intent)
{
case "diagnostic":
// Parallel: analyst + attribution
var diagTasks = new[]
{
_dataAnalyst.RunAsync(question, dateRange),
_attribution.RunAsync(dateRange.Start, dateRange.End)
};
await Task.WhenAll(diagTasks.Select(async t => {
try { return await t; }
catch (Exception ex) {
state.Errors.Add(ex.Message);
return new Dictionary<string, object>();
}
}));
state.DataAnalystOutput = await diagTasks[0];
state.AttributionOutput = await diagTasks[1];
// Then diagnostics
state.DiagnosticsOutput = await _diagnostics.RunAsync(
state.DataAnalystOutput);
break;
case "attribution":
state.DataAnalystOutput = await _dataAnalyst.RunAsync(
question, dateRange);
state.AttributionOutput = await _attribution.RunAsync(
dateRange.Start, dateRange.End);
break;
case "campaign":
state.DataAnalystOutput = await _dataAnalyst.RunAsync(
question, dateRange);
state.DiagnosticsOutput = await _diagnostics.RunAsync(
state.DataAnalystOutput);
break;
default: // reporting
state.DataAnalystOutput = await _dataAnalyst.RunAsync(
question, dateRange);
break;
}
// Narrative agent covered in Part 2
return state;
}
}
Errors in One Agent Don't Crash the Run
The asyncio.gather(return_exceptions=True) pattern in
Python (and the equivalent try/catch per task in C#) means that if the Attribution
Agent fails — say, because there are no conversion touchpoints in the date range —
the orchestrator still returns whatever the Data Analyst Agent produced. The error
is logged to state and surfaces in the narrative as a gap, not a crash. This
partial-failure-tolerance is what makes the system usable in production, where data
is always messier than expected.
Streaming works by broadcasting agent completion events over SSE (Server-Sent Events). As each agent node completes in the LangGraph graph, the API server emits a message to the client: "Analyzing attribution data..." appears on screen within seconds of the question being asked. By the time the Narrative Agent finishes, the user has already seen three intermediate progress updates. The blank-screen wait becomes a visible workflow.
ROI and Business Value: When Does This Pay Off?
I want to be direct about when this system makes economic sense, because it doesn't always. The math depends on two things: how much analyst time you're spending on ad-hoc analytics questions, and how much money you're deploying in marketing channels where attribution matters.
On the analyst time side: the system answers diagnostic questions in 30 seconds that would otherwise take 2-3 days of analyst time. If a data analyst costs $120K/year ($580/day fully loaded), a 3-day analysis costs $1,740. If you're running 4-6 of these per month, that's $7,000-10,000/month in analyst time on ad-hoc analytics. The system costs roughly $380/month at 100 queries/day (infrastructure + tokens — detailed in Part 2). The ROI is straightforward if the volume is there.
On the budget optimization side, the attribution modeling is where the real value surfaces.
The Attribution Reallocation Math
A $50K/month ad budget misallocated by 20% — common when teams rely on last-click attribution — burns $10K/month ineffectively. One Shapley attribution run that reveals the misallocation and informs a budget reallocation pays for six months of infrastructure. The system doesn't need to be right every week. It needs to be right once per quarter on a budget decision that matters.
This math holds at $20K/month ad spend and above. Below that, attribution signal differences are too small to surface actionable differences. Use a spreadsheet instead.
When it pays off: $20K+/month in ad spend across multiple channels, a marketing team of 3+ people asking analytics questions regularly, and a data pipeline that produces reliable conversion tracking.
When it doesn't (preview of Part 2's honest section): Small budgets where channel differences don't reach statistical significance. Teams where decisions won't change based on data. Organizations with broken UTM tracking or incomplete conversion events — the NL→SQL agent returns confidently structured wrong answers when the underlying data is dirty.
What We've Built — And What's Next
This is the foundation of a practical multi-agent marketing analytics system. What I've covered in Part 1:
- The six-agent architecture and why single-responsibility per agent matters
- The four-table marketing data warehouse schema and why read-only connections are non-negotiable
- The Data Analyst Agent: schema injection, query validation, and sanity checking
- The Attribution Agent: five models including Shapley approximation via Monte Carlo sampling
- The Campaign Diagnostics Agent: threshold rules combined with LLM synthesis
- The Orchestrator: LangGraph state machine with four routing patterns and parallel execution
Part 2 completes the picture:
- Audience Segmentation Agent — RFM implementation with pandas and Semantic Kernel
- Narrative Agent — the citation enforcement pattern that prevents hallucinated metrics
- Real token costs per query type (diagnostic query: ~$0.09, weekly report: ~$0.05)
- Azure infrastructure breakdown: ~$380/month at 100 queries/day
- Observability: logging the SQL, the agent chain trace, and sanity check flags
- Five scenarios where you should NOT build this
- The C# vs Python decision framework for this specific architecture
Continue Reading: Part 2 — Production Considerations
Part 2 covers the Audience Segmentation and Narrative agents, real token costs, Azure infrastructure pricing, and when NOT to build this. Read Part 2 →
Want More Practical AI Tutorials?
I write about building production AI systems with Azure, Python, and C#. Subscribe for practical tutorials delivered twice a month.
Subscribe to Newsletter →