What This Article Covers
- Why the way public AI tools handle your data creates a liability you may not have accounted for
- Which industries are most exposed and why the risk is different from ordinary software
- What day-to-day work looks like before and after moving to an isolated AI setup
- How to calculate the financial case for private AI deployment against your own breach exposure
- The honest checklist: when isolated AI is worth building, and when you should walk away from the idea entirely
A partner at a mid-sized Sydney law firm asks an AI assistant to summarise a draft merger agreement. The document includes target-company financials, deal structure, break-fee terms, and board-level correspondence that hasn't been filed anywhere. The summary arrives in seconds. The partner uses it in a client call that afternoon. Three months later, a competitor surfaces in the same acquisition process with negotiating intelligence that mirrors the original document almost exactly.
The breach investigation takes eleven weeks. It traces back to the AI query. The public model processed the document on external servers. It retained fragments of the content. A similar query from another user — possibly a competitor's advisor using the same platform — surfaced related context. No server was hacked. No employee acted maliciously. The data leaked through an everyday productivity tool that everyone in the office was already using.
I'll address this upfront: I'm not saying public AI tools are untrustworthy in a general sense. For drafting blog posts, writing marketing copy, or summarising publicly available research, they're fine. The problem is specific — and it's one that healthcare administrators, fund managers, mine general managers, and government directors face every week without realising the exposure they're carrying.

1. Is This Right for Your Operation?
Before I explain how the risk works, I want to give you the honest filter. Not every organisation needs an air-gapped AI deployment. Some do. Here's how to tell the difference quickly.
Isolated AI Works Well If…
- Your teams regularly use AI tools to process documents containing client financials, patient records, case files, classified briefings, or proprietary operational data
- Your industry is subject to regulatory frameworks governing data residency or confidentiality — healthcare, finance, legal, government, defence, or critical infrastructure
- You've already deployed productivity AI tools and your governance team hasn't yet audited what data is being submitted to them
- You operate under contractual obligations (supplier agreements, client NDAs, government contracts) that restrict where data can be processed
- A single breach incident — reputational or regulatory — would cause material damage to your operation
Walk Away If…
- Your team only uses AI on marketing copy, public research, or data that carries no confidentiality obligations — public AI is fine for this
- You don't have the budget or internal capability to maintain an isolated model server over a 2–3 year horizon — a poorly maintained private deployment creates more risk than a managed public one
- Your organisation doesn't have at least one person who can manage infrastructure patching, model updates, and access control; isolated AI is not a "set and forget" deployment
- You are looking for a way to use AI on sensitive data without spending anything — isolated AI has real costs, and cutting corners on those costs defeats the purpose
2. What Changes Day-to-Day
Here's what I've seen derail otherwise sound projects: the assumption that isolated AI means a degraded experience. It doesn't. The shift is architectural, not experiential. Your staff use the same interfaces, the same query patterns, and the same output quality. The difference is entirely in where the data goes.
Before: Productivity With Hidden Exposure
A Monday morning in a typical mid-sized professional services firm. The compliance officer asks the team's shared AI assistant to compare two vendor contracts and flag deviations. The analyst uploads both PDFs. The AI returns a clean summary in 90 seconds. Everybody is pleased with the efficiency. Nobody notices that both contracts — containing counterparty pricing, liability caps, and confidentiality clauses — have just been processed on servers owned by a US-based technology company, under terms of service that permit use of submitted content for model improvement. The data has left the building. There is no audit trail. If either contract becomes the subject of a dispute, no one in the organisation can demonstrate where the content went or who may have accessed related context.
After: Same Speed, Zero Egress
The same Monday morning, six months after an isolated deployment. The analyst uploads the same contracts to the same interface. The AI returns a comparable summary in 95 seconds. The documents were processed on a server rack in the organisation's own data centre. Nothing left the network perimeter. The query is logged against the analyst's account. The compliance officer can pull an audit trail for any document that was ever submitted to the AI. If a regulator asks, there is a complete record. If a client asks, the answer is straightforward: their documents never left the organisation's infrastructure.
"The shift in mindset is from treating AI as a productivity tool to treating it as data infrastructure. Once you see it that way, the question of where the data goes becomes non-negotiable."
3. The Business Case
The number that surprises most people is not the cost of an isolated AI deployment — it's the cost of the breach it replaces. IBM's 2024 Cost of a Data Breach report puts the global average at $4.88 million per incident. For healthcare organisations, that figure rises to $9.77 million. For financial services, $5.90 million. For critical infrastructure operators, $4.97 million. A single regulatory fine in Australia under the Privacy Act 1988 (as amended) can reach $50 million for serious or repeated interference with privacy.
The business case for isolated AI doesn't require your organisation to have already experienced a breach. It requires an honest estimate of three things: how frequently your teams are submitting sensitive data to public AI tools, what a breach of that data would cost you, and what an isolated deployment costs to build and maintain. In most cases I've worked through, isolated AI pays back within 14–24 months on breach risk reduction alone — before accounting for the operational productivity gains from deploying AI on data that was previously too sensitive to touch.
ROI Calculator — Breach Risk vs. Isolated AI
Adjust the sliders to match your operation. Results update in real time.
Calculator assumes a 65% reduction in breach probability with isolated AI deployment. Project cost is estimated at $140,000 base plus $120 per 100 monthly queries. Annual infrastructure is $36,000. Regulatory fine exposure is not included — add that separately.
Sensitive Data Exposure Incidents Per Quarter — Before and After Isolated AI
Q1–Q4 2025 shows baseline exposure incidents using public AI tools. Q1 2026 shows a transition quarter (partial rollout). Q2–Q4 2026 shows the reduction after full isolated deployment. Q1 2026 spikes slightly as teams consolidate from multiple public tools to a single governed platform before the private model is live.
4. How the System Works
Be sceptical of any vendor quoting an isolated AI deployment as a simple swap. What you are actually building is a complete data processing environment that sits inside your own network perimeter. Here's what that looks like in six stages.
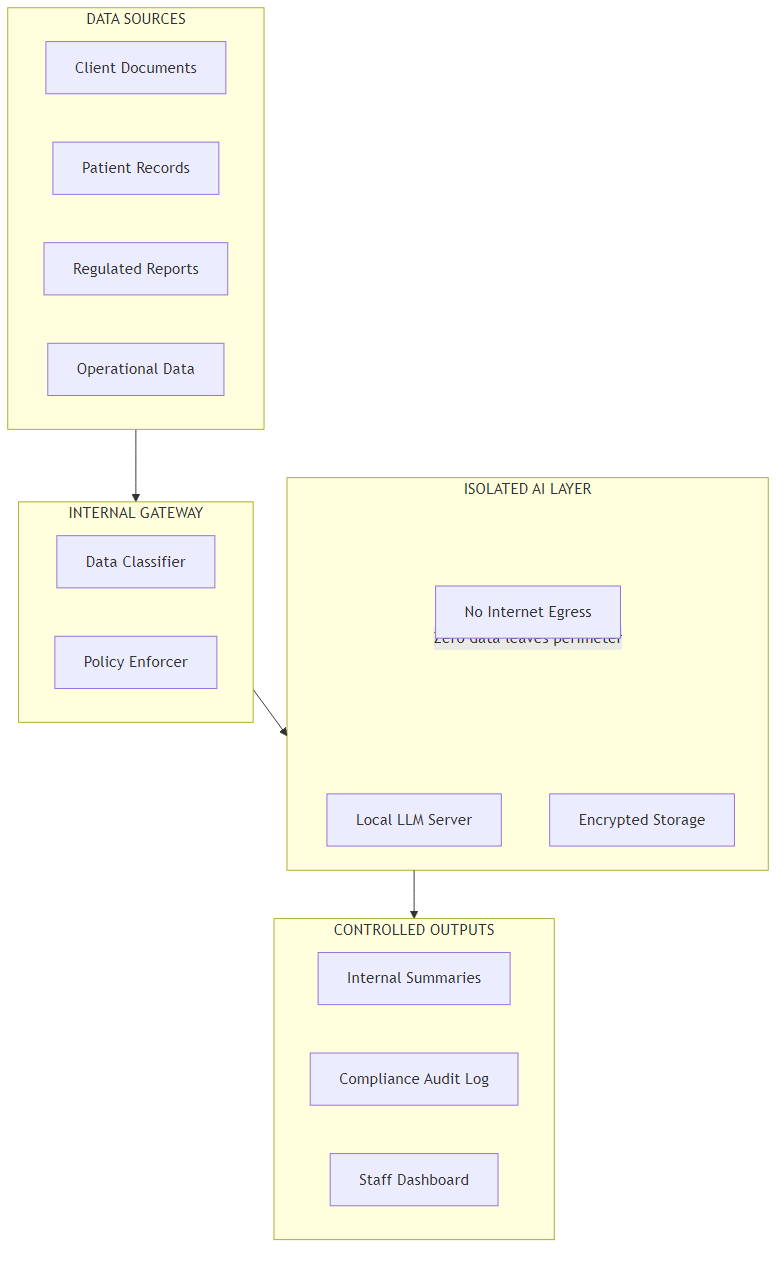

Stage 1 — Data Enters the Internal Gateway. Documents, records, and data queries originate from within your network. A data classifier checks content against your governance policy before the AI ever touches it. Queries that don't meet the policy are returned to the user with a clear explanation.
Stage 2 — Policy Enforcement. Your organisation sets the rules: what data types can be submitted to which AI functions, who is authorised to submit what, and what logging is required. The policy enforcer applies these rules at the gateway layer — not inside the AI model where they'd be invisible to your governance team.
Stage 3 — Isolated Model Processing. The approved query reaches the local language model server. This server has no outbound internet connectivity. It cannot call external APIs, phone home to a vendor's telemetry endpoint, or log query content anywhere outside your infrastructure. The model runs on hardware you own or lease exclusively.
Stage 4 — Encrypted Storage. Any data retained for context, session history, or audit purposes is stored in an encrypted data store inside your perimeter. Encryption keys are held by your team, not a third-party provider.
Stage 5 — Output Generation. The AI response is generated and returned to the requesting user through the same internal channel. The summary, analysis, or answer never travels over the public internet.
Stage 6 — Audit Trail. Every query is logged against the user account, document reference, timestamp, and policy classification. If a regulator asks what happened to a document, you can answer with a complete record. If an employee misuses the system, you can trace exactly what was submitted and when.
5. How the AI Data Risk Actually Works
Most leaders I speak with assume that data submitted to a public AI tool is handled the way data submitted to a search engine is handled — anonymised, processed briefly, then discarded. The reality is more complicated, and the distinction matters enormously for regulated industries.
The Key Distinction: Processed vs. Retained
When you submit a document to a public AI assistant, three things happen that don't happen with a search engine:
- The content is sent to external servers that are typically located in a foreign jurisdiction, outside your regulatory perimeter.
- The content may be used to improve the model under terms of service that many enterprise users have not read carefully. "Opt out" options exist for some platforms, but they're not universal, not always retroactive, and not always verifiable.
- The content is processed alongside queries from other users on shared infrastructure. While vendors take steps to isolate sessions, the fundamental architecture is multi-tenant. A well-crafted prompt from another user can sometimes surface context from previous sessions on the same infrastructure.
The analogy I find most useful: think of a public AI platform like a shared photocopier at a business centre. It works fine for copying a menu or a conference flyer. You would not use it for a merger agreement or a patient diagnosis. The risk isn't that someone is actively watching — it's that you have no visibility, no control, and no audit trail over what happens to the copy once you walk away.
An isolated AI deployment changes all three of the risks above. Your data doesn't leave your servers. It isn't used for model training. It's processed on hardware you control, and the query log is yours. The model's output quality is comparable to the public alternative — the major models available for private deployment (open-weight models in the 7B–70B parameter range) now perform at a level that meets the productivity requirements of most enterprise use cases without requiring a public internet connection.
6. What It Costs
I'll be direct about costs here, because this is where most project proposals I've reviewed have been either too optimistic or deliberately vague. There are two categories of cost: the one-time project cost to build the deployment, and the ongoing annual cost to run it.
| Running Cost Item | Typical Annual Cost | Notes |
|---|---|---|
| Dedicated GPU server (leased) | $24,000–$48,000 | Depends on model size and concurrent user load |
| Infrastructure management | $18,000–$30,000 | Patching, monitoring, access control updates |
| Model licensing (open-weight) | $0–$12,000 | Open-weight models are often free for enterprise use; some require commercial licences |
| Security audit (annual) | $8,000–$15,000 | Penetration testing and access log review |
| Staff training and governance | $5,000–$10,000 | Annual refresher and policy update cycle |
| One-Time Project Cost Item | Typical Cost | Notes |
|---|---|---|
| Infrastructure setup and configuration | $35,000–$55,000 | Server provisioning, network isolation, firewall rules |
| Model selection and fine-tuning | $20,000–$40,000 | Selecting the right model for the use case; domain-specific tuning if required |
| API and integration development | $25,000–$45,000 | Connecting the model to existing document management, ERP, or case management systems |
| Data governance framework | $15,000–$25,000 | Policy design, classification schema, audit trail setup |
| Pilot and validation | $10,000–$20,000 | Controlled testing before full deployment |
The Number That Surprises Most People
The most common budget error in isolated AI projects is underestimating the ongoing cost of infrastructure management. The server is not the hard part — keeping it patched, monitored, and auditable over a 3-year operational life is where projects run over budget. Build $18,000–$30,000 per year into your ongoing model before you sign anything. If a vendor quotes you significantly less than this for a fully managed private deployment, ask exactly who is patching the server, who holds the encryption keys, and who is responsible if a vulnerability is discovered after deployment.
Where Your Data Risk Budget Currently Goes
The red slice — reactive breach remediation — is the target. Isolated AI shifts spend from reactive damage control to planned, auditable infrastructure.
7. What Your Team Needs
Here's what I've seen derail otherwise sound projects: launching an isolated AI deployment without having the internal capability to maintain it. This is not a vendor-managed SaaS subscription. It requires real ownership inside your organisation.
The minimum viable internal team is:
- One infrastructure owner — responsible for server health, patching schedule, and access control. Does not need to be a data scientist. A senior IT administrator with Linux server experience can fill this role.
- One data governance owner — responsible for the classification policy, who can submit what data to the AI, and the quarterly audit of query logs. This is typically your compliance or legal officer with 2–4 hours per month of dedicated AI governance time.
- One technical integration lead (for the build phase only) — connects the AI layer to your existing systems. This can be an external contractor for the initial 3–6 months, with handover to your internal infrastructure owner.
On build vs. buy: the honest answer is that most organisations in the 200–2,000 staff range are better served by a specialist implementation partner than by building everything in-house. The reason is model selection and integration — choosing the right open-weight model for your specific use cases, and connecting it cleanly to your document management or case management system, requires specialised knowledge that's hard to develop internally for a one-time deployment. Operations and maintenance, once the system is live, can almost always be handled by your existing IT team.
| Phase | Duration | Key Activities | Who Leads |
|---|---|---|---|
| 1. Data governance audit | Weeks 1–3 | Map which data types your teams are currently submitting to public AI tools. Classify by sensitivity and regulatory exposure. | Internal compliance officer |
| 2. Use case prioritisation | Weeks 4–5 | Identify the 3–5 highest-value AI use cases that are currently blocked by sensitivity concerns. Rank by business impact. | Business unit leads + IT |
| 3. Infrastructure build | Weeks 6–12 | Server provisioning, network isolation, model deployment, initial integration with document management system. | External implementation partner |
| 4. Pilot and validation | Weeks 13–16 | Controlled rollout to one business unit. Test output quality, logging, access control, and policy enforcement against real use cases. | Internal IT + pilot business unit |
| 5. Full deployment and handover | Weeks 17–20 | Full org rollout. Staff training. Handover of infrastructure ownership to internal team. First governance review scheduled. | Internal IT (primary) |
| 6. Ongoing operations | Ongoing | Monthly patching cycle, quarterly audit log review, annual model update assessment, annual security audit. | Internal infrastructure owner |

8. How You Know It's Working
The metrics for isolated AI governance are different from the metrics you'd track for a standard IT project. You're not measuring system uptime alone — you're measuring whether the deployment is actually reducing your data exposure and producing the productivity outcomes that justified the investment.
| Metric | What It Measures | 12-Month Target |
|---|---|---|
| % of sensitive AI queries routed through isolated system | Whether staff have actually transitioned from public tools to the private deployment | 95% of document-processing queries through isolated system |
| Policy exception rate (queries blocked at gateway) | Whether the classification policy is calibrated correctly — too high means policy is too restrictive; too low means data is getting through that shouldn't | Under 3% exception rate; exceptions reviewed weekly |
| Audit log completeness | Whether every query is being captured with the required metadata for regulatory purposes | 100% query logging; monthly audit report generated |
| Patch currency (days since last security patch) | Whether the infrastructure is being actively maintained, not just monitored | Zero critical patches outstanding; patches applied within 14 days of release |
| Staff-reported productivity change | Whether the isolated system is delivering comparable productivity to public tools, or creating friction that will drive shadow IT behaviour | Neutral or positive in 80% of quarterly staff survey responses |
9. Where to Start
In practice, the right starting point for most organisations is not a full deployment. It's an honest audit of what's already happening. Here are five specific actions, in order.
- Conduct a shadow AI audit in the next 30 days. Ask each business unit to list every AI tool currently being used, including free consumer tools. Don't assume the answer is "just the approved ones." In my experience, most professional services organisations discover 4–8 unsanctioned AI tools in active use when they ask the question directly. Map what data is being submitted to each.
- Classify your data by sensitivity tier. Not all sensitive data carries the same risk. A three-tier classification — public, internal, regulated — is usually sufficient for an initial deployment. Regulated data (health records, legal documents, financial client data, classified government content) goes into the isolated system. Internal data can often stay on managed public AI with appropriate access controls. Public data needs no restriction.
- Identify your three highest-value blocked use cases. Where are your teams currently avoiding AI because the data is too sensitive? Document summarisation, contract comparison, clinical note analysis, financial modelling with client data — these are the use cases that justify the investment. Quantify the time cost of doing these manually at current staff rates. That's your productivity ROI figure.
- Brief two or three specialist implementation partners. Not general IT vendors — organisations with specific experience in private language model deployment for your industry. Ask for a fixed-price proposal for a 4-week proof of concept on your top use case. The PoC will tell you more than any vendor presentation.
- Put the governance framework in place before the first query goes through the system. The classification policy, access control matrix, and audit log format should be designed and signed off before the isolated model receives any production data. Retrofitting governance onto a live AI deployment is significantly harder and more expensive than building it in from the start.
Key Takeaways
Five Decisions This Article Should Help You Make
- Is the risk real for your organisation? Use the shadow AI audit in Step 1. If your teams are submitting regulated data to public tools — and in most organisations, they are — the exposure is already active.
- Is the business case there? Use the ROI calculator above with your own breach cost estimates. If the payback is under 24 months on breach risk reduction alone, the numbers support the project.
- Do you have the internal capability? You need one infrastructure owner and one governance owner at minimum. If you don't have those roles available, build that into the project scope before you start.
- Should you build or buy? For organisations under 2,000 staff, an implementation partner for the build phase — with handover to internal IT for operations — is almost always the right model. Full in-house builds are appropriate for organisations with 10+ person IT teams and significant security infrastructure already in place.
- What does good look like? By month 12, 95% of sensitive AI queries should be routed through the isolated system, audit logs should be complete, and your governance team should be able to answer any regulator's question about document handling in under an hour.
Want Practical Insights on AI in Operations?
I write about applying AI to real business problems — with honest numbers and no vendor speak. Subscribe for articles delivered twice a month.
Subscribe to Newsletter →